
ABAP Open SQL, Condiciones en los filtros
IN con tabla de rangos
En los filtros de las sentencias Open SQL se permite utilizar con la adición IN una tabla interna de rangos para filtrar la información. Esta lección trata de enseñarle cómo aplicar correctamente este procedimiento.
- Sintaxis
… col [NOT] IN seltab …
Esta expresión es verdadera si el valor de la columna “col” (no) es en el conjunto de resultados descrito en las filas de la tabla de selección “seltab”. Cualquier tabla interna con un tipo de fila que corresponda a la de una tabla de rangos se puede especificar como “seltab” de tabla de selección.
La tabla de selección se evalúa de la misma manera que en las expresiones de comparación aparte del hecho de que en comparaciones con los operadores CP y NP la condición WHERE es sensible a mayúsculas y minúsculas, mientras que en otras expresiones de comparación no lo es. Los caracteres comodín “*” y “+” de las opciones de selección “CP” y “NP” se convierten en caracteres comodín OpenSQL “%” y “_”, por lo que el carácter de escape “#” también se maneja correctamente. Si “%” y “_” están contenidos en la plantilla, se genera un carácter de escape de OpenSQL.
- Tabla de rangos
Una tabla de rangos es una tabla interna con la misma estructura de una tabla de selección, por lo general una tabla de selección está formada por una tabla interna y una línea de cabecera, la tabla interna y su línea de cabecera está conformada por las siguientes cuatro columnas: SIGN, OPTION, LOW y HIGH. La columna SIGN acepta dos valores I para incluir y E para excluir. La columna OPTION acepta valores de los operadores binarios y LOW y HIGH representa el valor mínimo y máximo en cuanto se quiere especificar un intervalo. Para utilizar un único valor con los operadores binarios correspondientes (por ejemplo, EQ – igual a) debe especificarlo en la columna LOW y dejar la columna HIGH en blanco. El tipo de dato de las columnas LOW y HIGH deben ser del mismo tipo que el elemento donde se quiere comparar.
El siguiente ejemplo le enseñará las posibles opciones que admite una tabla de rangos:
| SIGN | OPTIONS | LOW | HIGH |
| I | EQ | 01104711 | |
| I | BT | 10000000 | 19999999 |
| I | GE | 90000000 | |
| E | EQ | 10000911 | |
| E | BT | 10000810 | 10000815 |
| E | CP | 1%2##3#+4++5* |
La siguiente condición WHERE se genera a partir del ejemplo:
… ( ID = ‘01104711’ OR
ID BETWEEN ‘10000000’ AND ‘19999999’ OR
ID >= ‘90000000’ ) AND
ID <> ‘10000911’ AND
ID NOT BETWEEN ‘10000810’ AND ‘10000815’ AND
ID NOT LIKE ‘1#%2##3+4__5%’ ESCAPE ‘#’ …
- Aplicación práctica
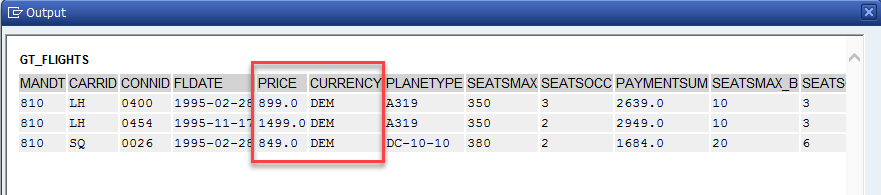
En un programa ejecutable realizamos una selección de datos de la tabla ZSFLIGHTSA00001 obteniendo en una tabla interna todos los registros con el precio entre 500 y 1500 DEM. Utilizamos una tabla con rangos en la operación de lectura.
- Implementamos el código fuente.
- Ejecutamos el programa.
Porque utiliza el WITH HEADER LINE. si ya es obsoleto.
Hola abap1,
Es correcto, el uso de tablas internas con cabecera ya es obsoleto. En versiones más recientes de ABAP, se alienta a los desarrolladores a declarar explícitamente las estructuras de datos para las tablas internas y utilizar estructuras para acceder a los elementos individuales de la tabla interna. Esto proporciona mayor claridad, flexibilidad y rendimiento en el código.
Este es un ejercicio que hemos hecho para ejemplificar el uso de tablas de rangos en las lecturas.
Pero lo más recomendable es usar estructura y tabla interna por a parte.
Un saludo.