
ABAP Open SQL, Lecturas en base de datos
Select Into Table
La sentencia SELECT [INTO|APPENDING] TABLE se utiliza para realizar lecturas en base de datos que obtienen más de un registro guardando en una tabla interna el resultado. Esta lección trata de explicarle todos los detalles que implica el uso de esta instrucción y cómo utilizar la sentencia SELECT [INTO|APPENDING] TABLE.
- Sintaxis
SELECT… { INTO|APPENDING
[CORRESPONDING FIELDS OF] TABLE itab } …
- Efecto
INTO específica a qué objetos de datos se asigna el conjunto de resultados de una instrucción SELECT o FETCH. Se puede especificar un solo área de trabajo wa o una lista de objetos de datos dobj1, dobj2, … después de INTO, o se puede especificar una tabla interna itab después de INTO o APPENDING.
La instrucción SELECT establece los valores de las variables del sistema SY-SUBRC y SY-DBCNT.
- SY-SUBRC:
- 0 La sentencia SELECT establece SY-SUBRC en 0 para cada valor pasado a un objeto de datos ABAP. La sentencia SELECT también establece SY-SUBRC en 0 antes de que salga de un bucle SELECT con ENDSELECT si se pasó al menos una fila.
- 4 La instrucción SELECT establece SY-SUBRC en 4 si el conjunto de resultados está vacío, es decir, si no se encontraron datos en la base de datos. Se aplican reglas especiales cuando sólo se utilizan expresiones agregadas en el resultado.
- SY-DBCNT
- Después de cada valor que se pasa a un objeto de datos ABAP, la sentencia SELECT establece en el valor de la variable del sistema SY-DBCNT el número de filas pasadas. Si se produce un desbordamiento porque el número o filas es mayor que 2,147,483,647, SY-DBCNT se establece en -1. Si el conjunto de resultados está vacío, SY-DBCNT se establece en 0. Al igual que con Sy-SUBRC, se aplican reglas especiales si sólo se utilizan expresiones agregadas en el resultado.
- Aplicación práctica
En un programa ejecutable realizamos una selección de datos en la tabla ZSPFLISA00001 obteniendo en una tabla interna todos los registros. Luego añadimos una línea en blanco en la tabla interna y realizamos de nuevo la misma lectura en base de datos añadiendo los mismos registros a los registros que existen en la tabla interna. Al finalizar mostramos en la salida el contenido de la tabla interna utilizando el método estático DISPLAY de la clase estándar CL_DEMO_OUTPUT.
- Implementampos el código fuente.
- Ejecutamos el programa.
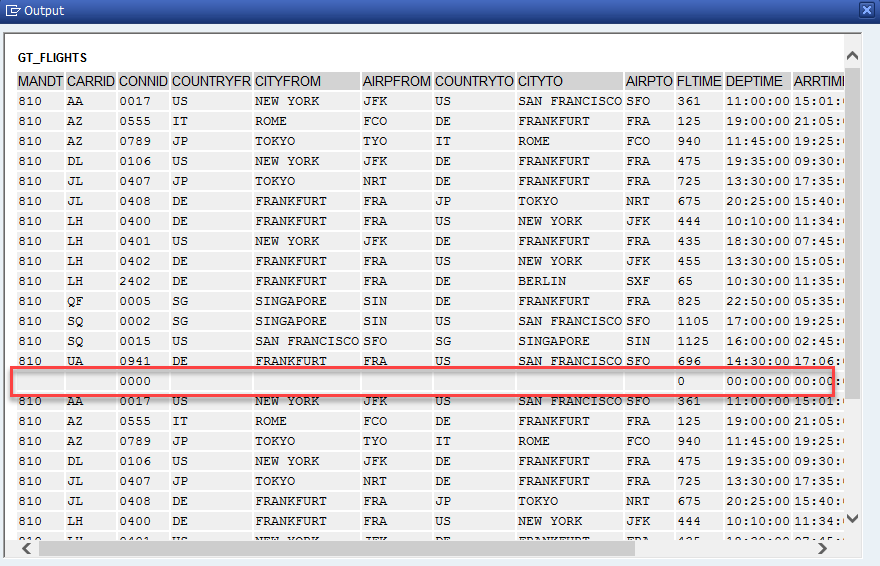
- Conclusiones
Con la adición INTO se eliminan los registros que existían en la tabla interna (si no es vacía) y se asignan los resultados que devuelve la lectura SELECT. Con la adición APPENDING se mantienen los registros que existían en la tabla interna (si no es vacía) y se añaden los resultados que devuelve el SELECT.
- Notas
- En temas de rendimiento los datos deben ser mejor leídos en una tabla interna o un área de trabajo dependiendo del tipo de procesamiento posterior: Si los datos se requieren sólo una vez en un programa, se debe importar en un área de trabajo, fila por fila. Leer datos en una tabla interna requiere más espacio de memoria (sin la desventaja) debido a una velocidad de lectura considerablemente más alta. Si, por otro lado, los datos se requieren muchas veces en un programa, se debe leer en una tabla interna. La desventaja del requerimiento de memoria incrementado es más que compensado aquí por la ventaja de una selección única.
- Si se van a importar datos en una tabla interna, es mejor importarlos una vez dentro de una tabla interna que colocarlos, fila por fila, en un área de trabajo y finalmente agregarlos a una tabla interna usando APPEND.
- Las variantes con la adición INTO CORRESPONDING FIELDS requieren un tiempo de ejecución mayor que las variantes correspondientes sin INTO CORRESPONDING FIELDS, sin embargo, el tiempo de ejecución es menos dependiente del volumen.
- Las variantes con la adición INTO CORRESPONDING FIELDS corren el riesgo de tener áreas de trabajo wa con más componentes que los que realmente se llenan. Esto sólo debería ser el caso si los componentes que no están llenos se llenan en el programa. De lo contrario, deben utilizarse áreas de trabajo de tamaño adecuado para evitar que se llene una gran cantidad de memoria por los valores iniciales (especialmente en las tablas internas).