

SAP CAP – Asociación versus Composición
Hemos llegado a la última parte de esta serie de blogs, en los cuales los primeros tres artículos hablan acerca de las restricciones o cardinalidades que puede haber entre las entidades. Esto quiere decir, que hasta este punto ya sabe definir una relación: uno a uno, uno a muchos y muchos a muchos. Además, aprendió cómo a nivel de base de datos es posible establecer relaciones por medio de la clave primaria y la clave foránea, e incluso vio el uso del parámetro $self el cual permite hacer una referencia hacia todas las claves primarias de una entidad sobre sí misma. En otro artículo podemos hablar únicamente del uso del $self.
Sin embargo, en el Modelo de Programación de Aplicaciones en la nube (CAP) hay dos maneras de poder establecer una relación, anteriormente en todos los ejemplos demostrativos lo hicimos con asociaciones (Associations), en esta oportunidad aprenderá que también es posible establecer una relación con composiciones (Compositions). Pero, ¿qué es una asociación y una composición? ¿Cuál es la diferencia entre una asociación y composición? ¿Cuándo usar una y cuándo usar la otra? Entonces, respondamos estas preguntas y luego reforcemos esos conceptos con algunos ejemplos prácticos.
Fundamentos básicos
¿Qué es una asociación?
Una asociación es una relación que se establece entre dos o más entidades. En donde a la entidad principal se le crea una referencia hacia la entidad destino. Sin embargo, cada una de las entidades pueden existir de forma independiente, ya que tienen un ciclo de vida distinto. En resumen, las asociaciones relacionan entidades que pueden existir independientemente una de otra, como por ejemplo Cursos / Estudiantes y Autores / Libros.
¿Qué es una composición?
Una composición es una relación que se establece entre dos o más entidades. En donde la entidad padre se vincula directamente con la entidad hija. Es decir, que la entidad hija depende directamente de la entidad padre. La entidad hijo no puede existir sin la entidad padre. Por ejemplo, imagine la entidad Pedidos con Artículos. Una composición significa que la entidad secundaria (elementos del pedido) es parte de un todo y no puede existir independientemente de la entidad principal (Pedidos). La entidad secundaria está contenida en la entidad principal y solo se puede acceder a ella a través de la entidad principal.
Pero, si tanto la asociación como la composición establecen una relación entre dos o más entidades, ¿cuál es la diferencia que hay entre ellas?
¿Cuál es la diferencia entre una asociación y una composición?
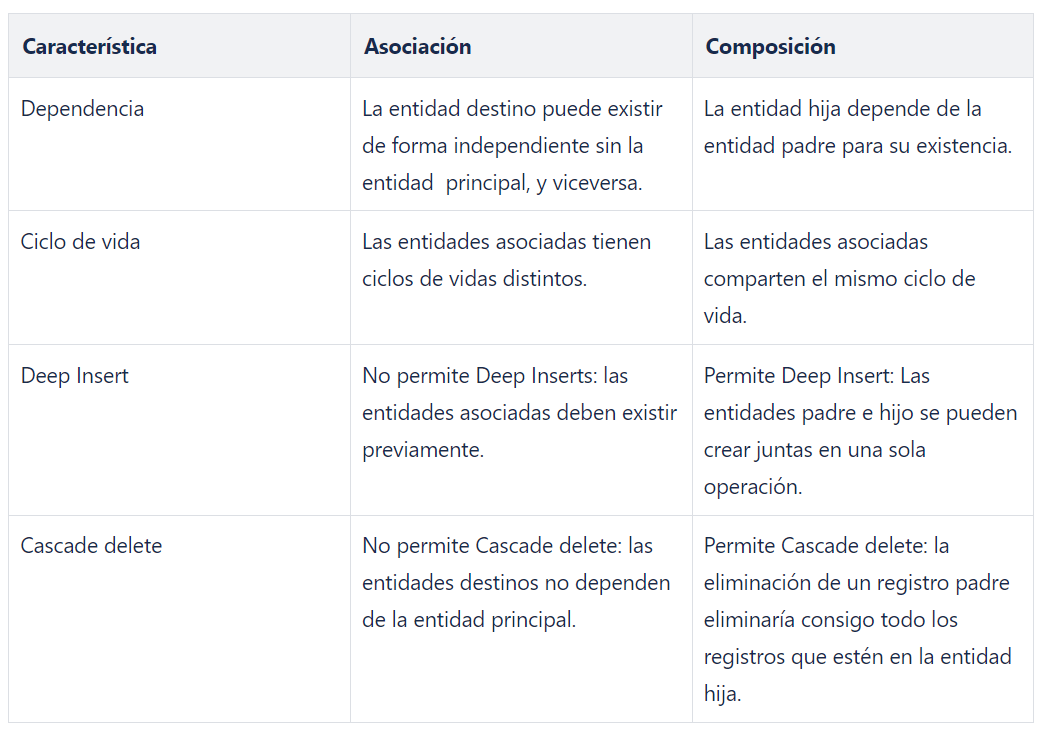
Observación: las composiciones son lo mismo que las asociaciones, solo con la información adicional de que esta asociación representa una relación contenida, por lo que se aplican la misma sintaxis y reglas en su forma básica.
¿Cuándo usar una asociación y cuándo usar una composición?
Responder esta pregunta, realmente no es tan efectiva si no se tienen claro los requerimientos o los procesos que se van a ejecutar. Sin embargo, dejaré adjunta algunas ideas generales para que puedas tomar la decisión correcta:
Asociación:
- Cuando las entidades deben ser independientes.
- Cuando la relación es opcional.
- Cuando diferentes entidades necesitan referirse a la misma entidad destino.
- Cuando las entidades requieren procesos independientes.
Composición:
- Cuando la entidad hija depende completamente de la entidad padre.
- Cuando sea necesario gestionar las entidades en forma conjunta.
- Cuando es necesario hacer un Deep Insert.
Es momento de ver toda la teoría en acción, y para ello veamos el siguiente ejemplo:
Ejemplo demostrativo – Associations
Lo que debe hacer es definir dos entidades: Departments y Employees con su respectiva relación uno a muchos, quedando el código de la siguiente manera, recuerde que debe crear un archivo llamado schema.cds dentro de la carpeta db.

En el código mostrado anteriormente, se puede notar, que hay una relación de uno a muchos desde la entidad Departments hacia la entidad Employees. La misma está habilitada para una navegación gracias al self. Entonces, una vez listas las entidades con sus asociaciones, es necesario que realice las proyecciones de las dos entidades. Para ello, cree dentro de la carpeta srv un archivo llamado: service.cds y copie el siguiente código:

Como resultado final debería tener las siguientes vistas:
Vista previa:
View: DepartmentsSet
View: EmployeesSet
Ambas entidades, como puede ver están listas pero no tienen ningún registro. Entonces, es momento de probar la teoría de los ciclos de vida independientes de cada una de las entidades así como el Deep Insert. Para ello, probemos la inserción de datos de forma manual tanto en la entidad: Departments y Employees.
POST – DepartmentsSet
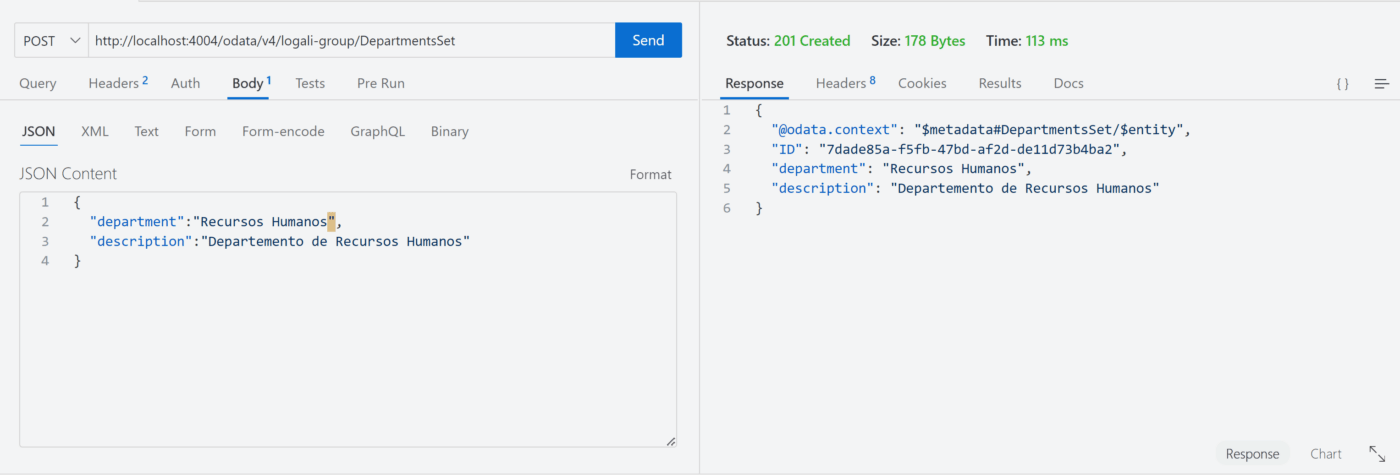
Como puede ver en la imagen previa, se hizo la inserción de un departamento en la entidad Departments y efectivamente se hizo el registro de forma exitosa. De igual manera, se puede verificar la existencia del mismo entrado en dicha entidad:
GET – DepartmentsSet
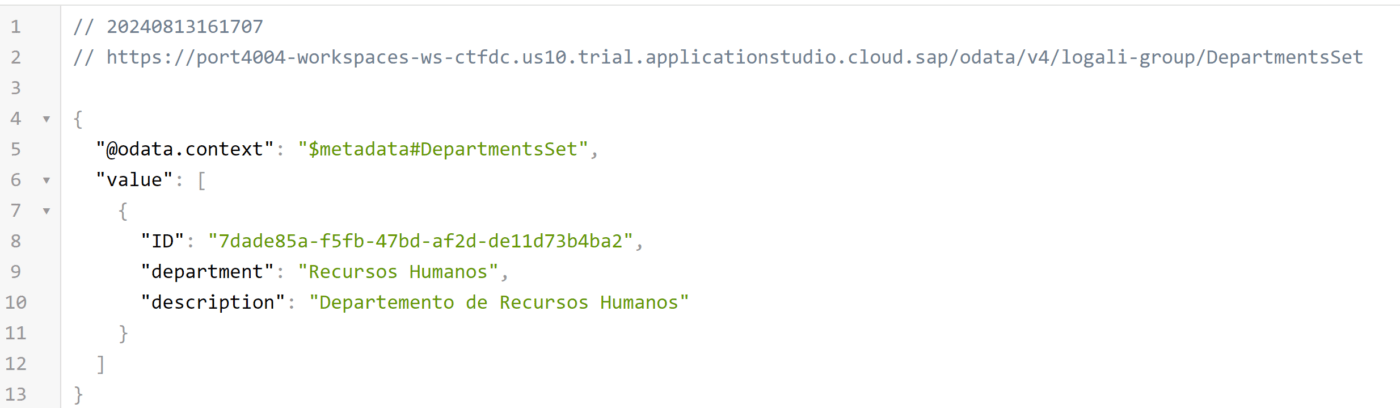
Ahora, repitamos el proceso para la entidad Employees, ya que en teoría es una entidad independiente. Es decir, que puede tener registro aunque exista o no algún departamento.
POST – EmployeesSet
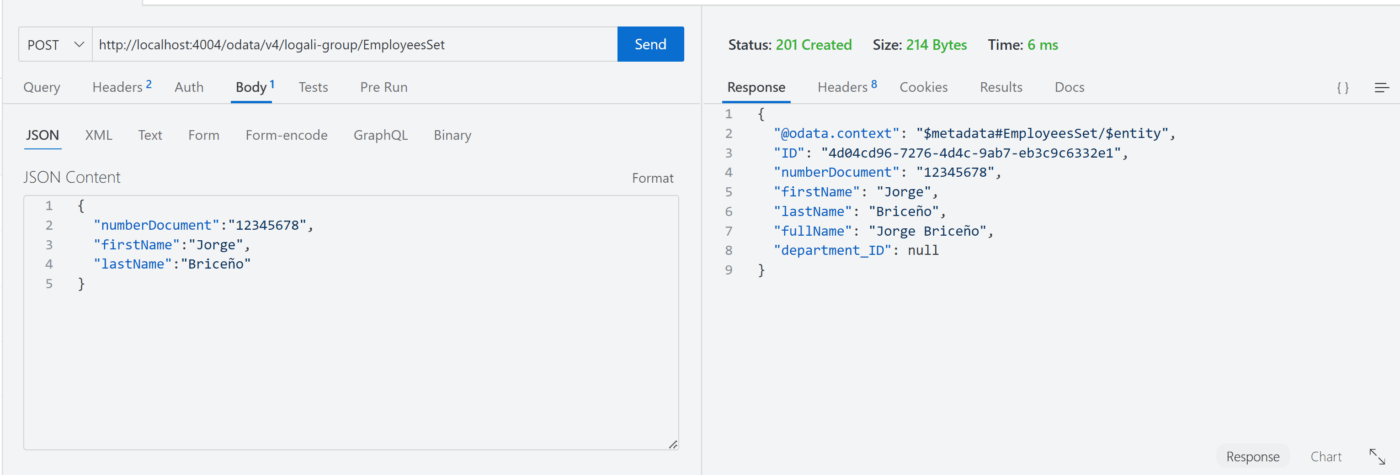
GET – EmployeesSet
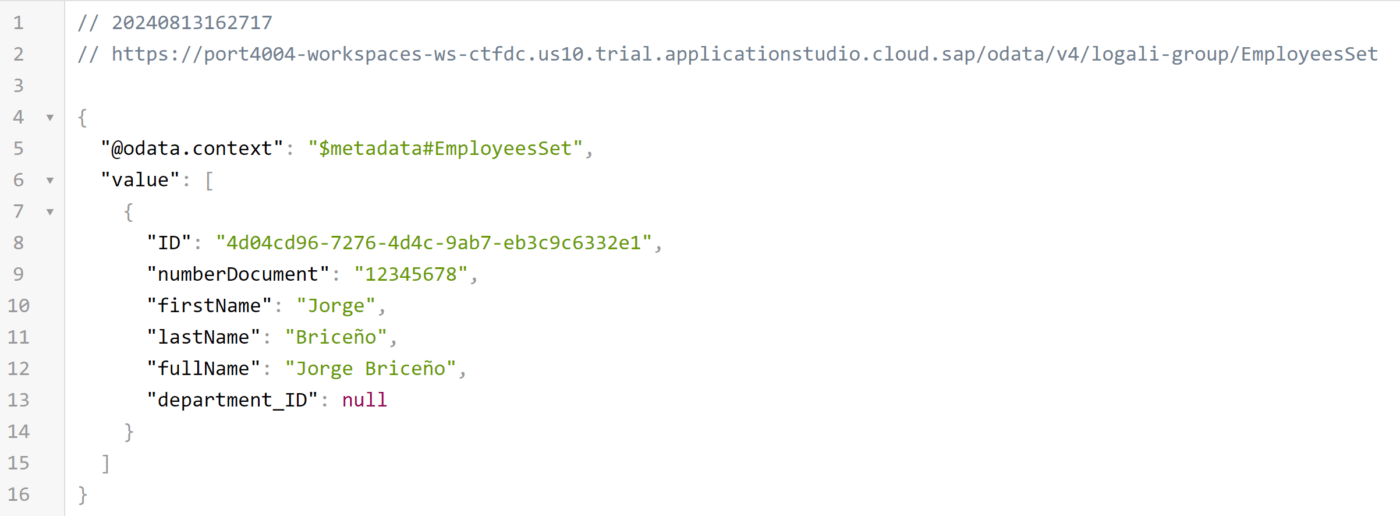
Como puede notar, efectivamente el registro de un empleado se hizo de forma exitosa. A pesar de tener una relación de uno a muchos, ambos registros se pueden crear de forma independiente. Esto confirma la independencia de ambas entidades. Además, es posible resaltar que el campo department_ID es null y esto quiere decir que, de momento el empleado no está asociado a ningún departamento.
En caso de querer asignar el empleado al departamento de Recursos Humanos, es necesario hacer una actualización del mismo, como se muestra a continuación:
PUT – EmployeesSet
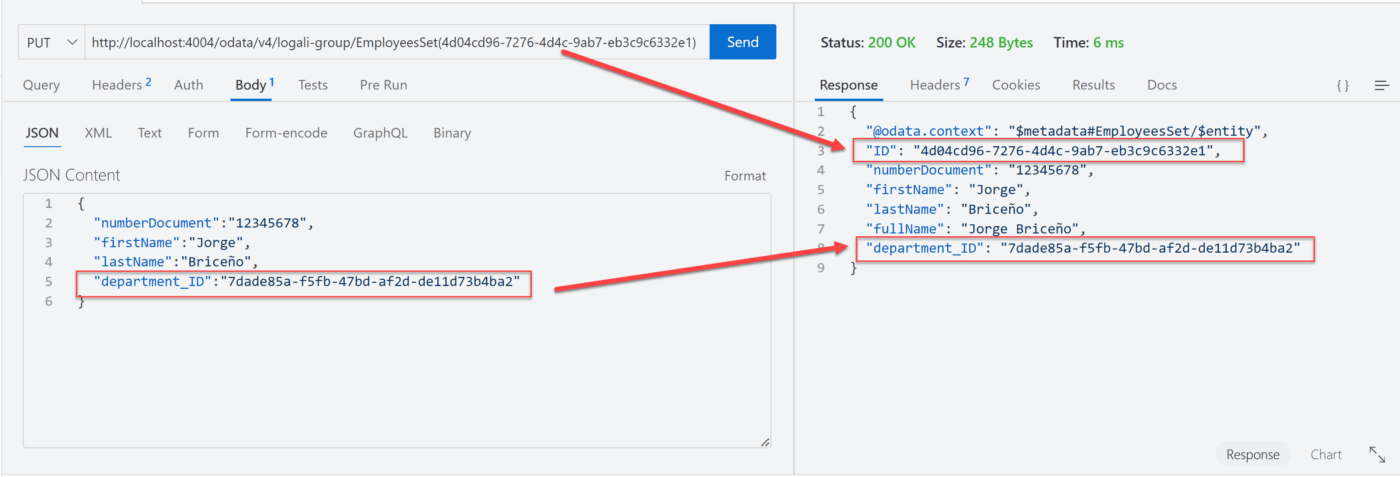
GET – EmployeesSet
En otro orden de ideas, faltaría comprobar si el Deep Insert funciona en relaciones con Associations. Para ello, intentaremos crear un departamento, incluyendo la creación de un empleado al mismo tiempo.
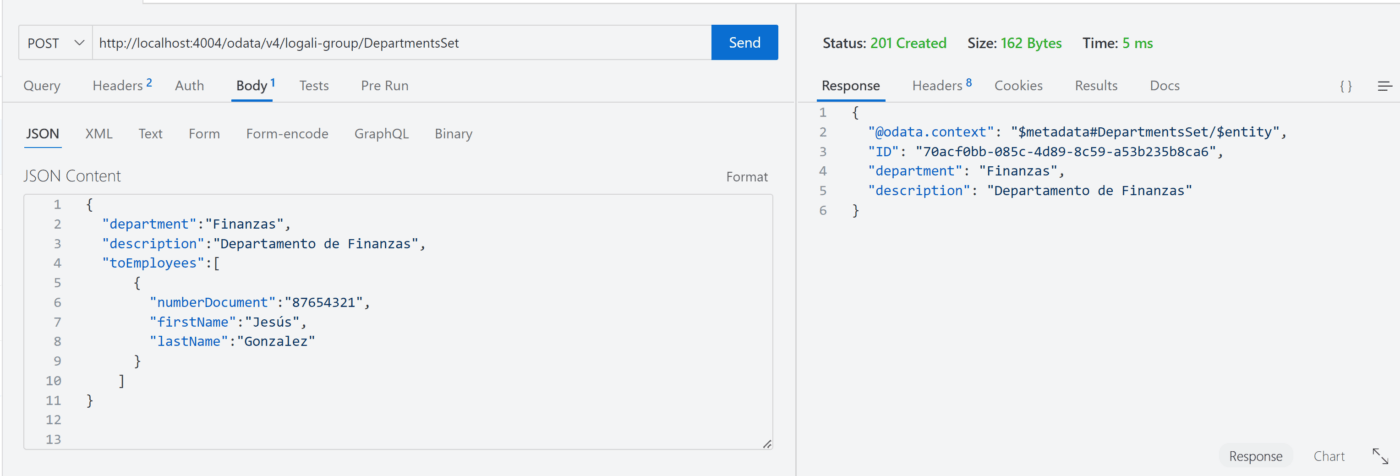
De acuerdo con la imagen previa, la inserción se hizo correctamente pero solo para la entidad Departments, el empleado al parecer no fue creado. Podemos verificar los mismos haciendo un GET en ambas entidades.
GET – DepartmentsSet
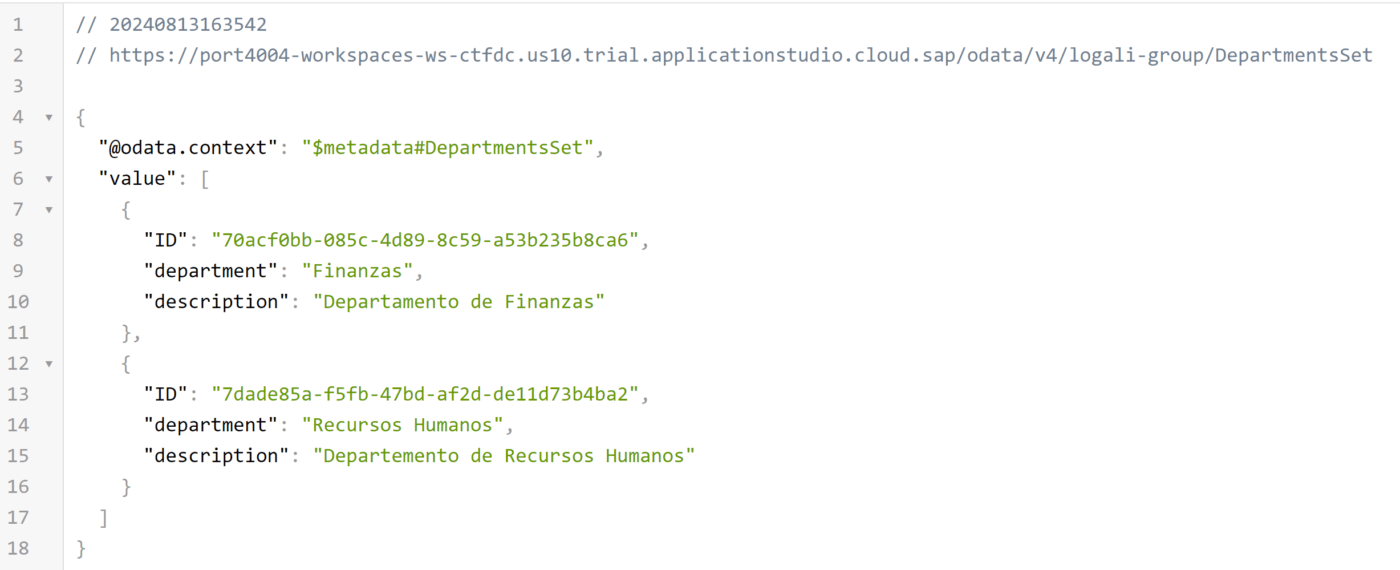
Como puede notar, efectivamente el departamento fue creado exitosamente. Ahora veamos la entidad de empleados:
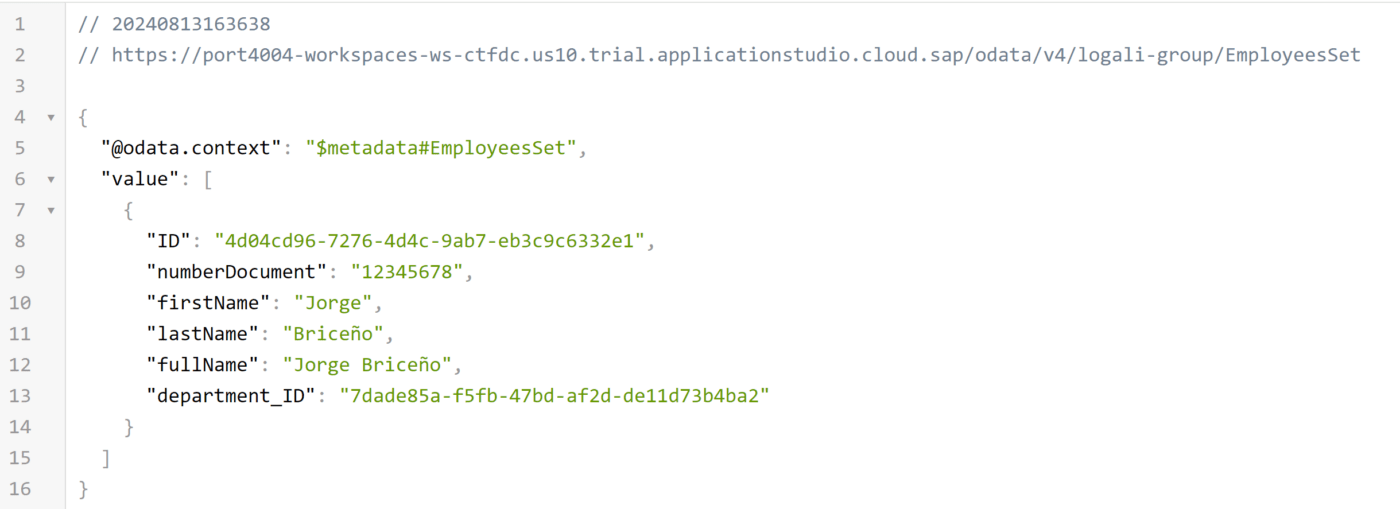
Tal como lo dice la teoría, con una relación tipo Association no es posible hacer una inserción profunda. Entonces, comprobemos si realmente con una relación tipo Composition es posible crear una Orden de compra y sus productos al mismo tiempo. Pero antes debemos ajustar, la relación entre las entidades.
En el caso de las asociaciones se utiliza:
- Association to → Relaciones uno a uno
- Association to one → Relaciones uno a uno
- Association to many → Relaciones uno a muchos
Para las composiciones se utiliza de la siguiente manera:
- Composition of → Relaciones uno a uno
- Composition of one → Relaciones uno a uno
- Composition of many → Relaciones uno a uno
Es momento, de ajustar la relación como se muestra a continuación:

Una vez listas las entidades con sus relaciones específicas, es necesario que realice las proyecciones de las dos entidades. Para ello, cree dentro de la carpeta srv un archivo llamado: service.cds y copie el siguiente código:

La proyección quedaría de manera similar al ejemplo anteriormente mostrado y como resultado final deberíamos obtener las mismas vistas previas del principio:
Vista previa:
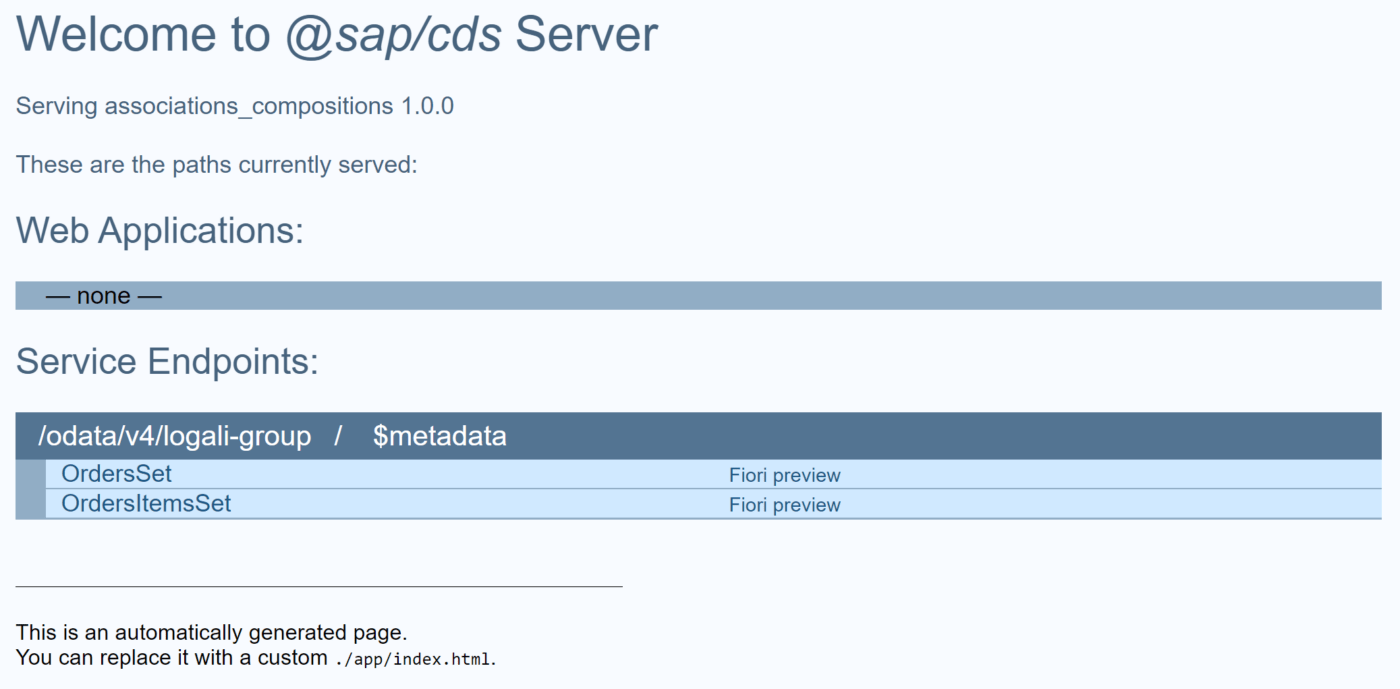
View: OrdersSet
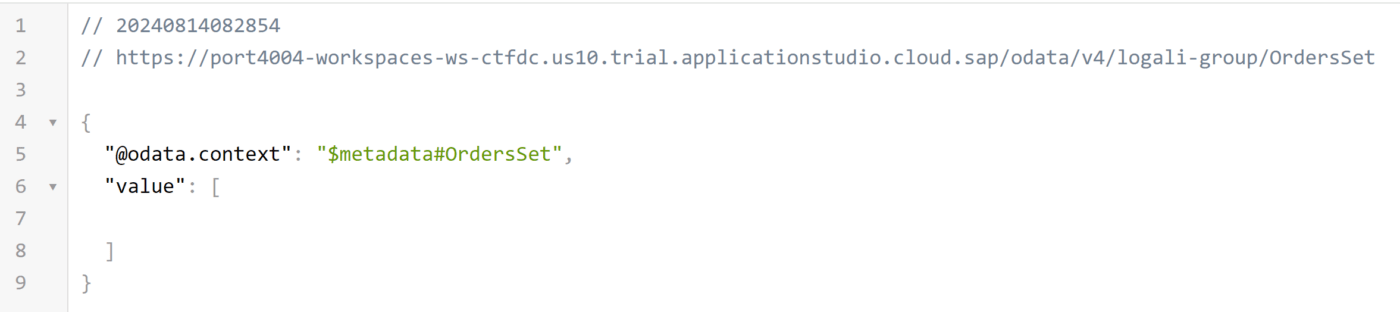
View: OrdersItemsSet
Pasemos ahora a intentar hacer un Deep Insert con la entidad Orders y OrdersItems. Para ello veamos la siguiente imagen:
Escenario – Crear una Orden de compra con sus productos al mismo tiempo
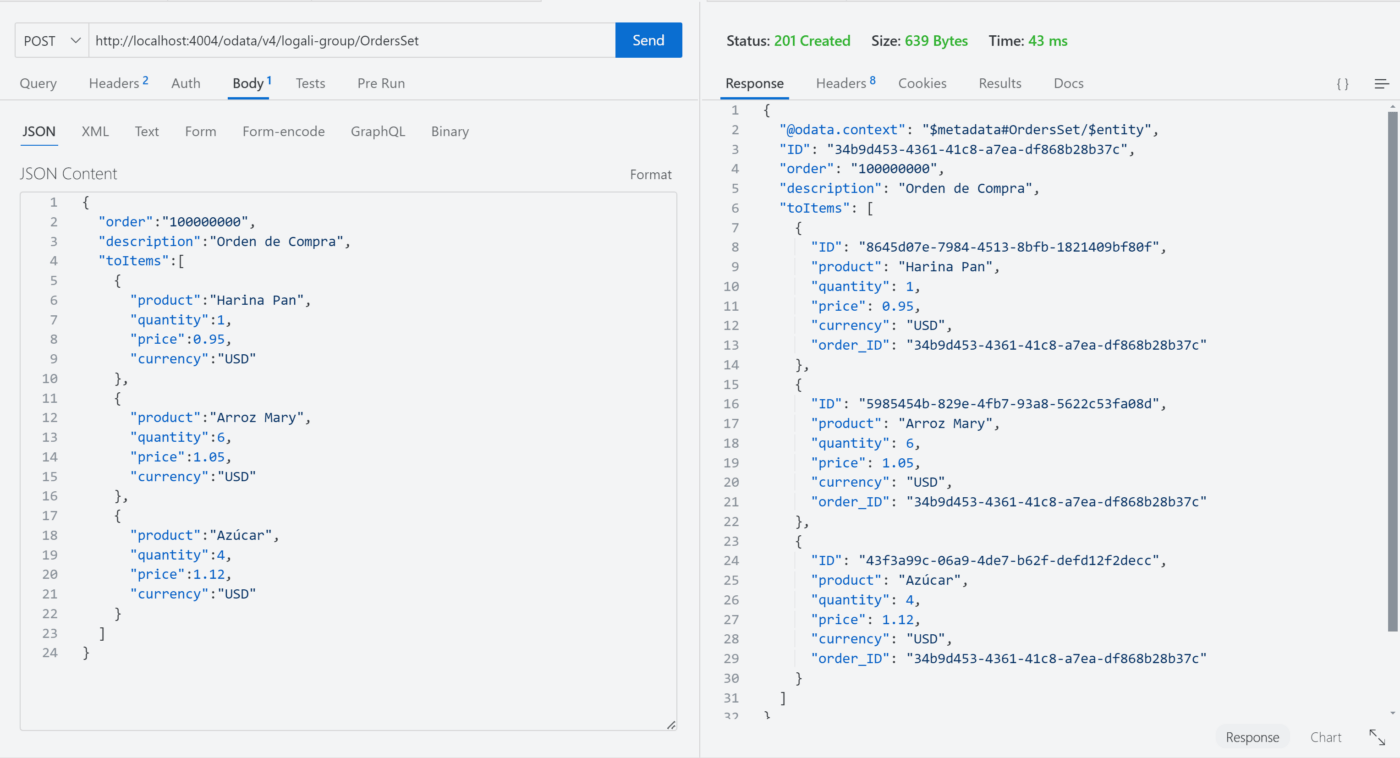
Observaciones: Como podrá notar, la inserción profunda fue realizada de forma exitosa. Esto quiere decir, que efectivamente sí es posible crear una Orden de compra con sus respectivos productos al mismo tiempo cuando la relación se establece con Composition of many. Incluso es posible verificar el mismo haciendo un GET a cada una de las entidades:
GET – OrdersSet
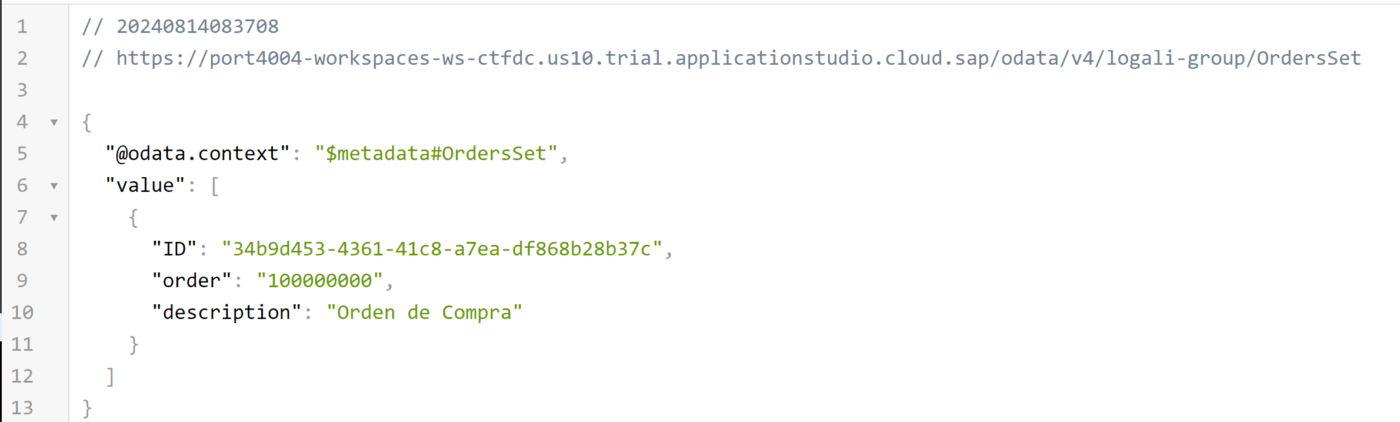
GET – OrdersItemsSet
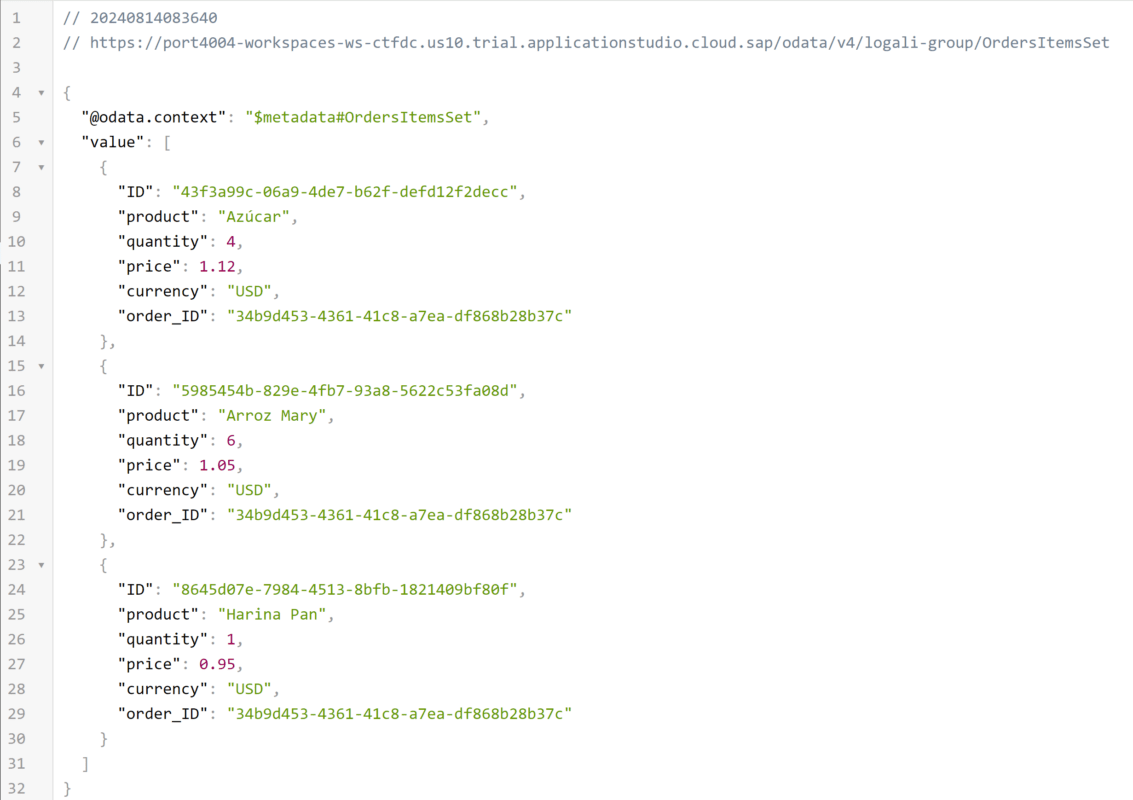
Como puede ver en ambas consultas están presentes los registros. Por otra parte, esto implica que no es posible crear un producto sin que el padre exista o puede que lo genere sin ningún order_ID. Pero lo que sí es posible, es crear un Orden de compra sin ningún producto. Comprobemos los dos escenarios:
Primer Escenario – Crear una orden de compra sin ningún producto
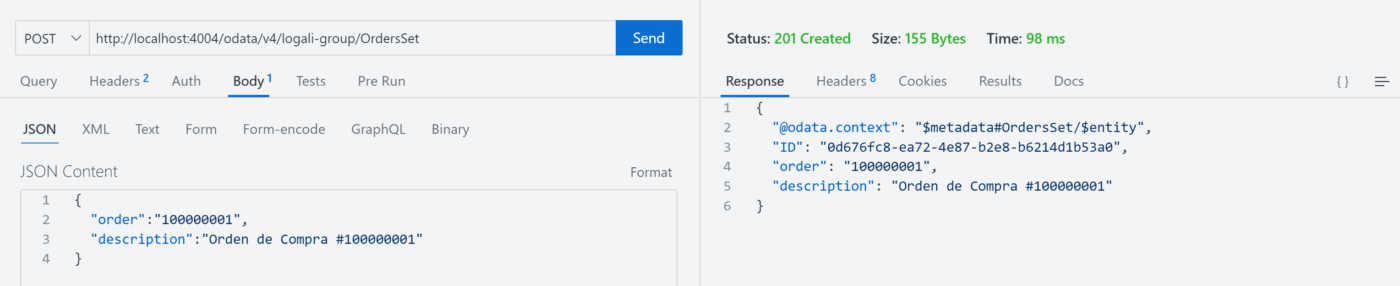
Observaciones:
Como puede ver en la imagen, es posible crear un registro en el cual solo se inserta una orden de compra sin sus productos.
Segundo Escenario – Crear un producto de forma independiente
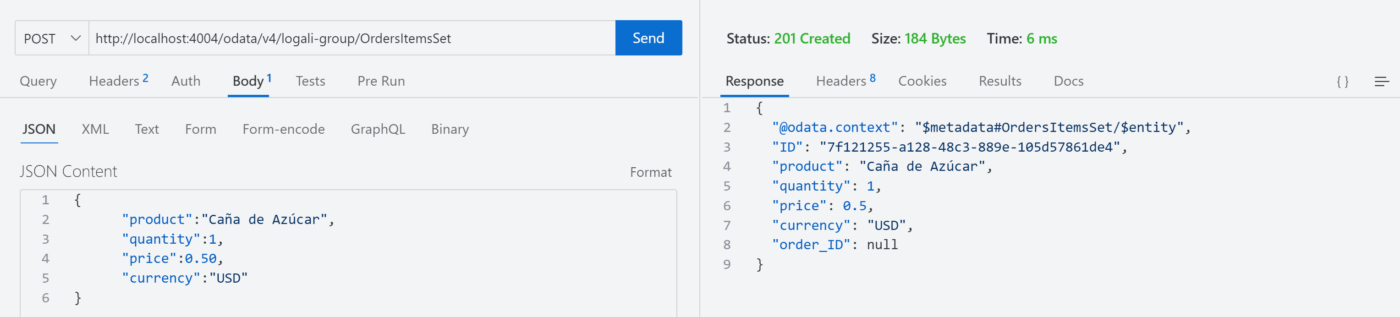
Observaciones: Como puede ver en la imagen, el producto fue generado de forma correcta en la entidad OrdersItems y de acuerdo con la teoría no es posible generar un producto sin que el padre exista, es decir, sin que la orden de compra no exista. Entonces, ¿Será un fallo o Flexibilidad?.
Veamos un caso donde en donde la teoría se ajusta perfectamente a lo indicado pero este escenario sólo es posible cuando se habilita el draft. De momento, no es nuestra intención hablar acerca del draft, por lo que solo se hará la demostración para fines de entendimiento, en el próximo artículo podemos hablar acerca del draft.
Tercer escenario – Crear un producto de forma independiente (Con draft)
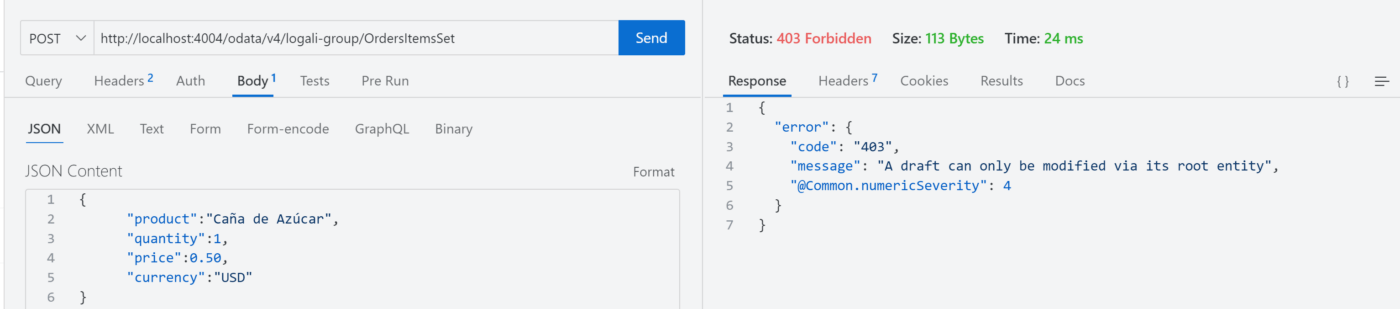
Observaciones: como puede notar en la imagen al intentar hacer nuevamente un POST pero con el draft habilitado nos muestra un mensaje que dice: “A draft can only be modified via its root entity“. Esto quiere decir, que solo es posible crear un producto desde la entidad principal, es decir la entidad Orden de compra.
Entonces, ¿cómo es posible que sin el draft habilitado no se cumpla la dependencia de una relación fuerte entre el hijo y su padre, tal como sucede cuando el draft está habilitado?
Respuesta
El comportamiento que estás observando cuando el draft está o no está habilitado tiene que ver en cómo CAP maneja los ciclos de vida de las entidades, especialmente cuando se usa el draft. Recordemos, que en una relación en donde el hijo depende fuertemente de su padre, a esto se le llaman composiciones en el modelado de datos. Esto quiere decir, que el ciclo de vida del hijo está intrínsecamente ligado al padre, lo que significa que si el padre es eliminado, todos sus hijos también lo serán. De igual manera, el hijo no puede ser creado o no puede existir si el padre aún no existe.
Sigo sin entender, ¿cómo es que este principio solo se aplica con el draft?
Cuando el draft no está habilitado, CAP permite cierta flexibilidad en cómo se gestionan las entidades. A pesar de que teóricamente una entidad hija no debería existir sin la entidad padre, el sistema puede permitir la creación directa de una entidad hija por razones de conveniencia o simplificación en la implementación. Sin embargo, esto va en contra del principio de composición, ya que técnicamente no debería persistir una entidad hija sin la existencia de la entidad padre.
Entonces, ¿qué funciones, reglas o directrices podría tener el draft?
Cuando el draft está habilitado, CAP introduce una capa adicional de gestión y control sobre las entidades. El draft permite la edición y revisión de datos antes de que sean definitivamente guardados en la base de datos. Esta funcionalidad implica un manejo más estricto de las relaciones de composición.
Pudiera decir, ¿que el draft es más estricto?
Con el draft habilitado, CAP aplica de manera más estricta las reglas de la composición, reforzando las entidades hijas para que solo se puedan crear a través de la entidad padre. Esto garantiza que no existan entidades hijas sin un padre válido y asegura que los cambios en la entidad hija estén siempre relacionados con un ciclo de vida válido del padre.
Es posible decir que: el draft asegura la coherencia de los datos, evitando que se creen entidades huérfanas que no deberían existir. Esta coherencia es especialmente importante en escenarios donde se necesita asegurar que todas las partes de una transacción o conjunto de datos estén correctamente relacionadas antes de su persistencia final.
A pesar de todo lo explicado anteriormente, hay alguna manera, camino o alternativa para poder controlar lo que es la inserción de un registro en la entidad hija?
Realmente, se podrían aplicar algunas anotaciones para controlar dicho aspecto pero seguramente no funcionan del todo. Veamos las anotaciones @assert.target y @assert.integrity.
@assert.target: sirve para verificar si la entidad de destino a la que hace referencia la asociación (el destino de la referencia) existe. En otras palabras, utilice esta anotación para verificar si una entrada de clave externa no nula en una tabla tiene una clave principal correspondiente en la tabla de destino asociada o referenciada. La restricción de verificación (@assert.target) está pensada para validar la entrada del usuario y no para garantizar la integridad referencial. Para garantizar que cada clave externa no nula de una tabla tenga una clave principal correspondiente en la tabla de destino asociada o referenciada (garantizar la integridad referencial), se debe utilizar la restricción @assert.integrity en su lugar.
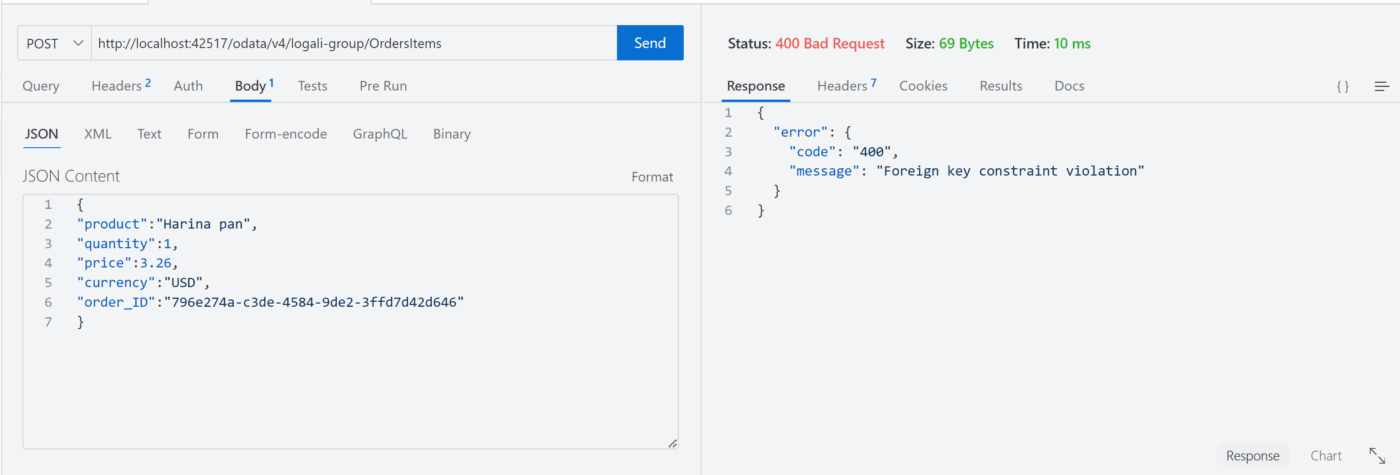
Suponga, que el order_ID “796e274a-c3de-4584-9de2-3ffd7d42d646“ no existe en la base de datos.
Primer escenario – @assert.target

Respuesta del servidor
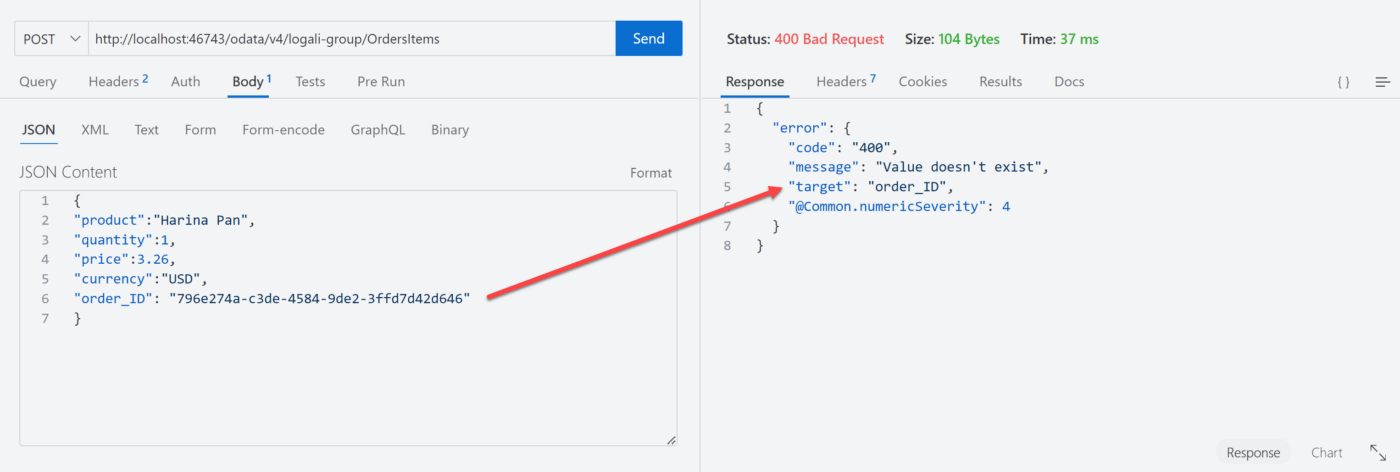
Como puede ver en la imagen, la respuesta del servidor fue que el valor order_ID no existe en la base de datos.
Segundo escenario – @assert.integrity

Respuesta del servidor:
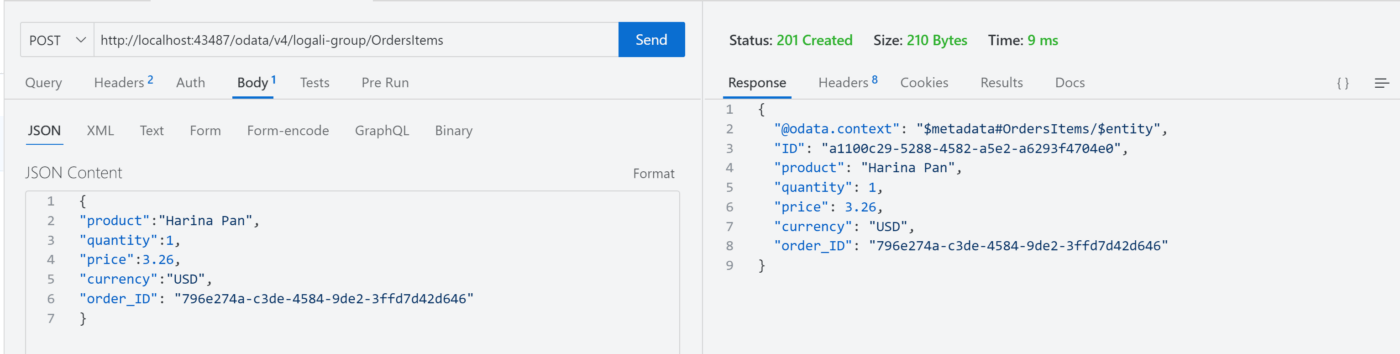
Como puede ver en la imagen, el servidor respondió con código 200, es decir que hizo la inserción del Item a pesar de que ID del campo order_ID no existe en la base de datos. Para solucionar esta situacion es necesario habilitar de forma manual la integridad de los datos ya que no están habilitadas de forma predeterminada, hágalo explícitamente configurando:
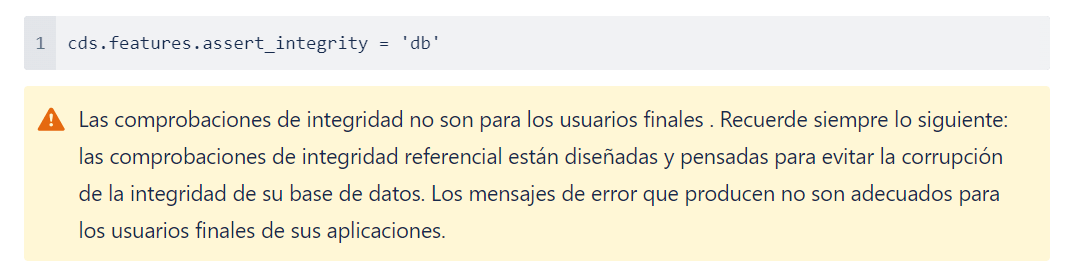
Una vez dicho lo ante expuesto, vamos al package.json a realizar el ajuste respectivo:

Seguidamente procedemos hacer la inserción de datos nuevamente:
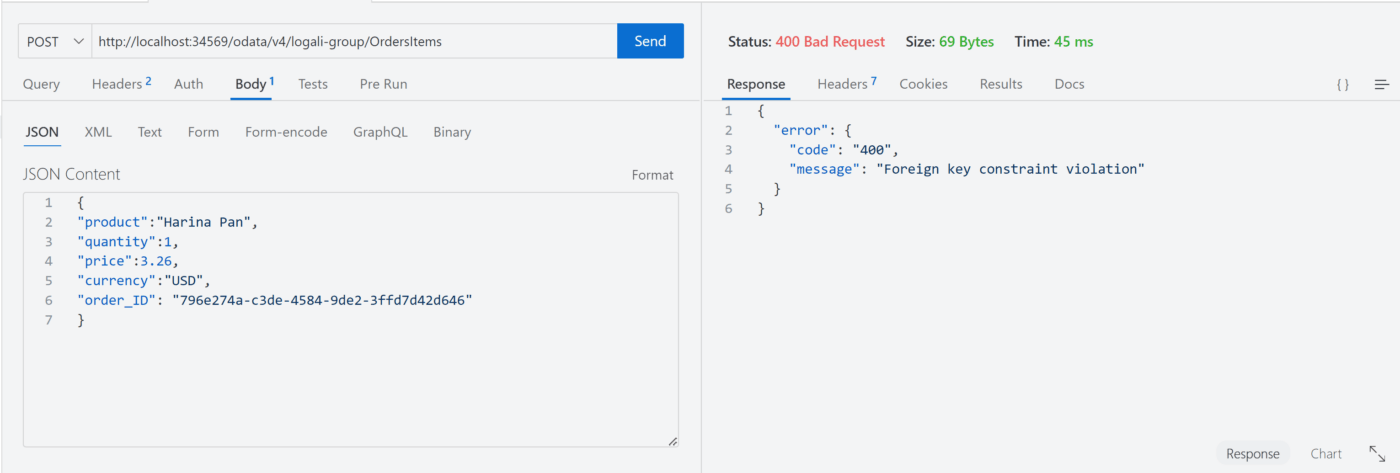
Como podrá ver en la imagen, la respuesta del servidor fue que: “Foreign key constraint violation“. Es decir, que dicho ID no existe en la base de datos por lo tanto no es posible hacer una referencia hacia el mismo. Sin embargo, ambas anotaciones tienen un debilidad y es que para que puedan funcionar se debe pasar el ID, en este caso el campo order_ID debe tener algún valor, ya que si lo dejamos que se asigne de manera automática, la respuesta del servidor será con código 200 y el campo order_ID pasar a ser nulo. Procedamos a probar dichos escenarios:
Tercer escenario – @assert.target sin el campo order_ID

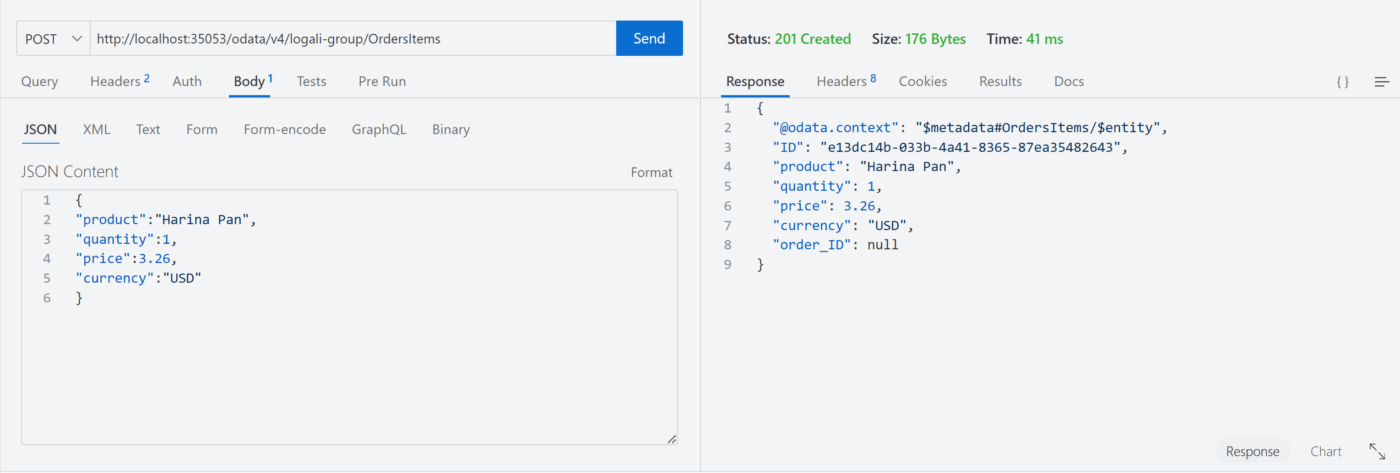
Cuarto escenario – @assert.integrity sin el campo order_ID

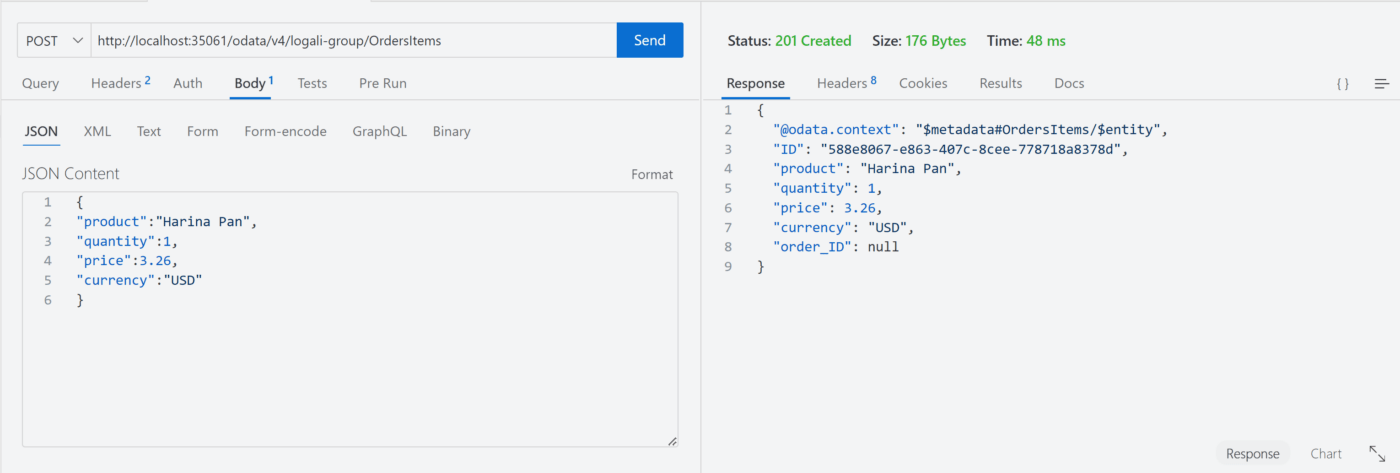
En ambos escenarios ocurrió algo indeseado, el registro fue creado pero con el order_ID nulo a pesar de ser una relación definida como una composición y para este caso se podría utilizar la anotación @mandatory o agregar directamente el not null sobre la asociación.
Quinto escenario – @mandatory

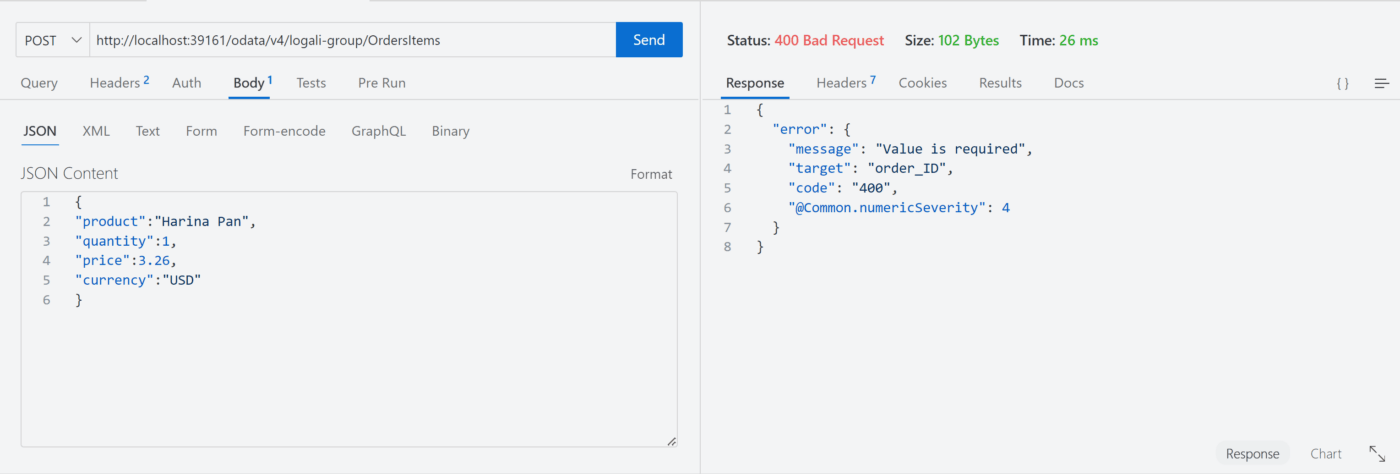
En la imagen puedes notar, que la anotación @mandatory está exigiendo un valor ya que es un campo obligatorio y lo mismo aplica si el valor va como nulo.
Sexto escenario – not null

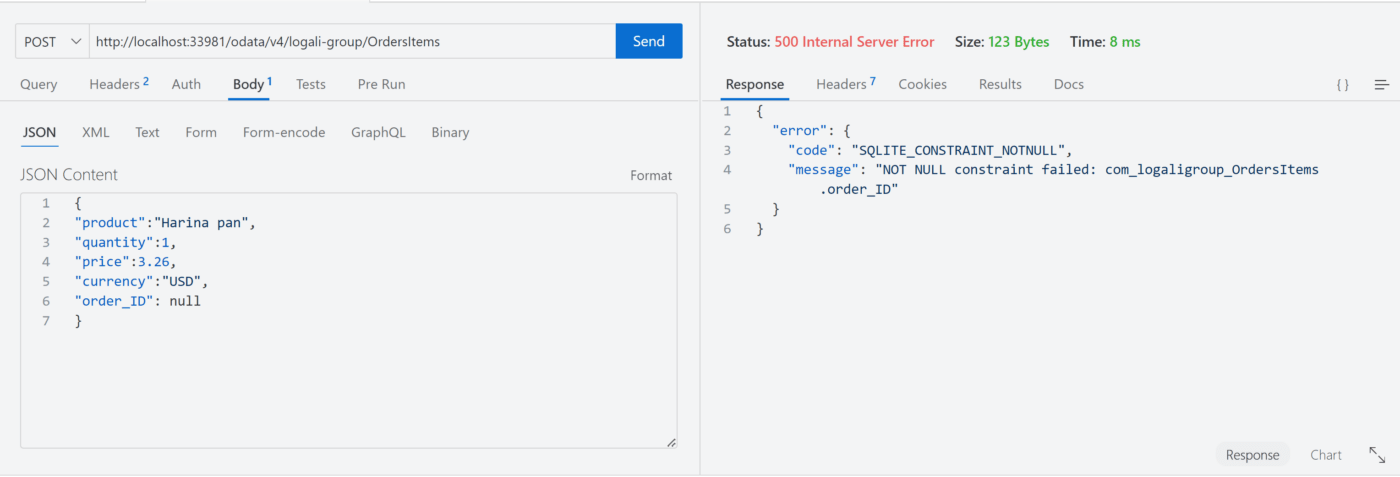
Al ver la respuesta del servidor, es posible notar que no se puede enviar el campo order_ID nulo, pero si es posible enviar un ID errado, entonces lo mejor para este escenario es combinar el not null con el @assert.integrity y de esta manera te aseguras que no vaya nulo y que no haga la inserción de ID errado.
not null y @assert.integrity con el campo order_ID como nulo
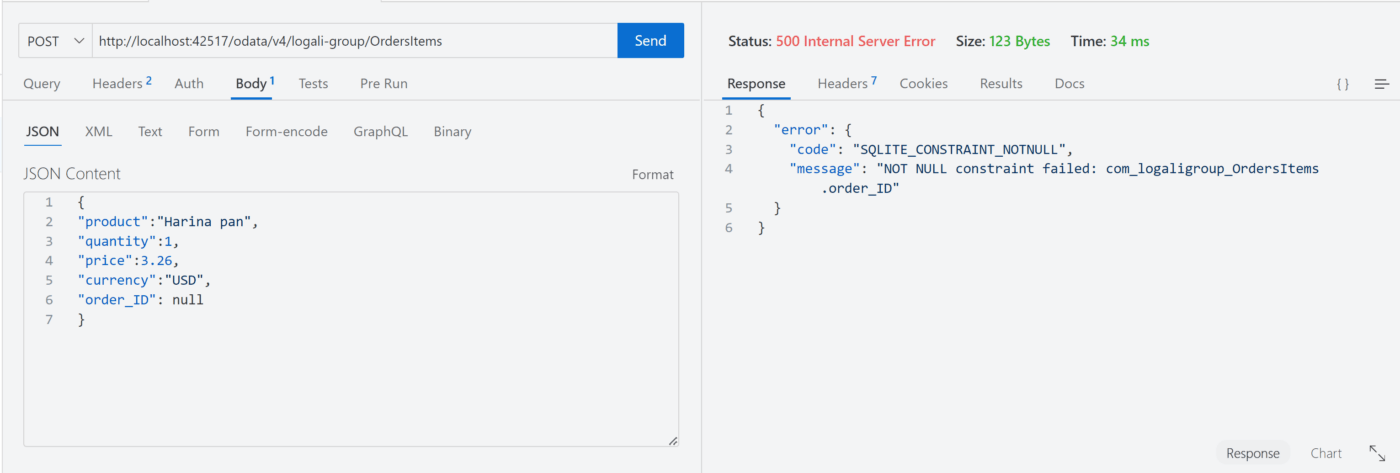
not null y @assert.integrity sin el campo order_ID
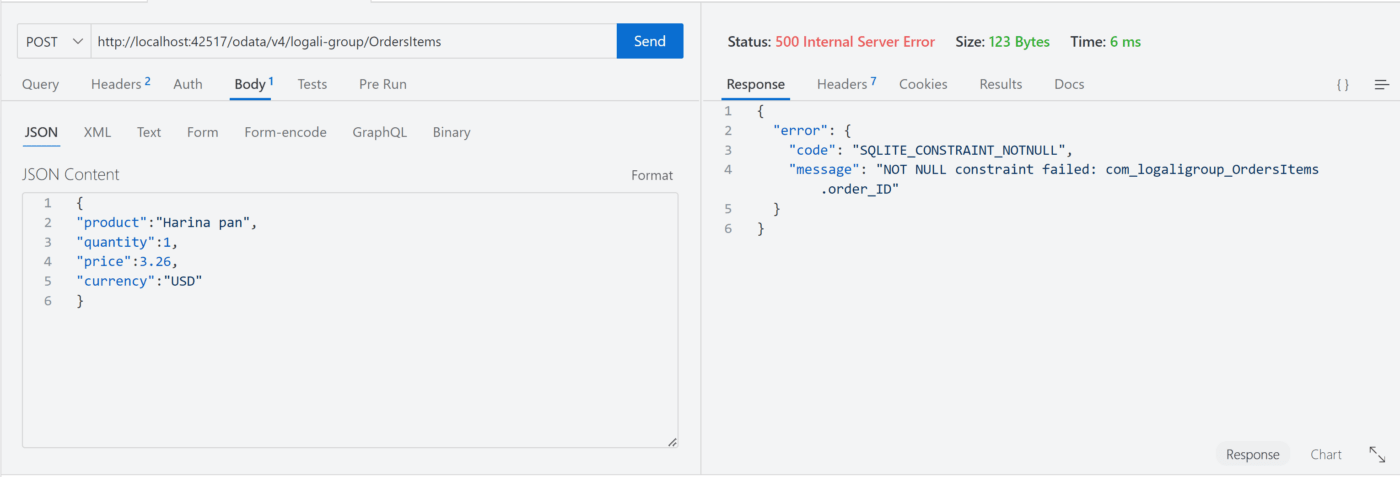
not null y @assert.integrity con el campo order_ID y un ID inexistente
En conclusión, a pesar de tener una relación como una composición por sí sola no puede funcionar si no agregamos capas de seguridad adicionales que puedan respetar la integridad de los datos. Por otra parte, la razón por la que CAP permite la creación de entidades hijas sin un padre cuando el draft no está habilitado podría ser vista como una debilidad o limitación en la implementación del framework. Esto tendríamos que preguntárselo a los creadores de SAP. Sin embargo, cuando se habilita el draft, es lógico notar que se refuerzan las reglas para garantizar que el modelo de datos respete estrictamente las relaciones de composición, tal como se espera teóricamente.
- Otra razón por la cual CAP está permitiendo crear una entidad hija sin el draft, pudiera ser porque para poder ejecutar el CRUD dentro de una plantilla Fiori Elements, es obligatorio tener el draft habilitado, de lo contrario las operaciones Create y Update no están disponible desde dichas plantillas. Esto podría ser la razón de por qué sin el draft es posible crear un registro en una entidad hija, ya que la validación está a nivel de anotaciones y no del servicio OData.
Conclusión
Las asociaciones y composiciones son dos tipos de relaciones que definen como las entidades están conectadas o vinculadas entre sí, pero difieren en la manera en que manejan la dependencia y el ciclo de vida de las entidades relacionadas.
Asociaciones: son un tipo de relación débil, ya que la entidad hija puede existir sin la entidad padre y pueden existir de manera independiente. Esto, quiere decir que la modificación o eliminación de la entidad padre no afecta en lo absoluto a las entidades hijas.
Composiciones: son un tipo de relación fuerte, ya que la entidad hija depende completamente de la entidad padre. Si el padre es eliminado, los hijos también se eliminan.
Por otra parte, de momento tenemos una flexibilidad si el draft no está habilitado, es decir, que hay más libertad (y riesgo) en la creación de entidades hijas. Sin embargo, con el draft habilitado, CAP impone un control más fuerte, asegurando que las entidades hijas solo existan dentro del contexto de una entidad padre válida, lo cual es consistente con el principio de composición. Este enfoque dual asegura que, en entornos más controlados y críticos (como cuando se utiliza draft), se respete completamente la integridad referencial y la relación de dependencia entre entidades padre e hija.