DataPrivacy, SAP, SAP BTP, SAPHANA, Sin categoría
Desarrollo nativo SAP HANA en Business Application Studio: del módulo MTA a las vistas de cálculo seguras

Cuando hablamos de desarrollar sobre SAP HANA, la conversación moderna gira en torno a CAP, RAP y aplicaciones full-stack. Pero hay un terreno donde el desarrollo nativo sobre HANA sigue siendo insustituible: cuando necesitas modelar datos analíticos complejos, exponer cálculos a velocidad in-memory o gestionar capas de seguridad y privacidad directamente en la base de datos.
Ese desarrollo nativo dejó de hacerse en el viejo SAP HANA Studio hace tiempo. Hoy el sitio donde construyes proyectos HANA Native es SAP Business Application Studio (BAS), el IDE en la nube de la Business Technology Platform (BTP). Y el objeto que articula todo es un proyecto MTA (Multi-Target Application) con su correspondiente módulo db, que empaqueta tablas, vistas, sinónimos y permisos en un contenedor HDI desplegable.
En este artículo recorremos el ciclo completo: cómo se prepara el entorno, cómo se construye un módulo de base de datos que combina contenedor HDI con esquemas clásicos, y cómo se modela una vista de cálculo de tipo cubo con anonimización de datos. Es decir, lo que necesitas para entregar un proyecto HANA Native real, no un “hello world”.

Contenido
Índice
- Por qué el desarrollo HANA nativo sigue siendo relevante
- El stack: BTP, HANA Cloud y SAP Business Application Studio
- Suscripciones, roles y permisos: la parte que más duele
- Anatomía de un proyecto MTA con módulo db
- Tablas, índices de texto y carga inicial
- Esquemas clásicos vs contenedor HDI: el puente con sinónimos
- Vistas de cálculo: del cubo al modelo analítico
- Anonimización en HANA: privacidad por diseño
- Buenas prácticas y errores frecuentes
- Conclusión
Por qué el desarrollo HANA nativo sigue siendo relevante
Hay una percepción extendida de que con la llegada del CAP (Cloud Application Programming Model) y de RAP (RESTful ABAP Programming Model), el desarrollo nativo sobre HANA quedó relegado. No es así.
Cuando una aplicación necesita modelos analíticos complejos, vistas con jerarquías, agregaciones avanzadas o capas de seguridad y enmascaramiento que se aplican directamente sobre los datos, lo que tienes debajo del CAP o del Fiori sigue siendo un modelo HANA nativo. La diferencia es que ahora vive dentro de un contenedor HDI (HANA Deployment Infrastructure), gestionado de forma declarativa con artefactos versionados.
Tres escenarios donde el HANA nativo es la mejor herramienta disponible:
Conocer este nivel ya no es opcional para un consultor SAP que se mueve en el mundo BTP. Es el cableado interior de muchas soluciones modernas.
El stack: BTP, HANA Cloud y SAP Business Application Studio
El escenario tiene tres piezas que conviene tener claras antes de empezar.
SAP BTP (Business Technology Platform) es la plataforma cloud donde SAP reúne todos sus servicios de desarrollo, integración, datos e inteligencia artificial. Es donde compras, suscribes y gobiernas las herramientas.
SAP HANA Cloud es la encarnación cloud de HANA. Una instancia gestionada por SAP que expone exactamente las capacidades del HANA on-premise (y algunas exclusivas), con un modelo de consumo elástico y su propio sistema de administración (HANA Cockpit, HDI, etc.).
SAP Business Application Studio es el IDE en la nube. Es la evolución del antiguo SAP Web IDE y reemplaza al HANA Studio de escritorio para los proyectos modernos. Trabajas en un dev space preconfigurado con las extensiones que necesitas según el tipo de aplicación: Fiori, Full-Stack Cloud Application, HANA Native, etc.
La combinación de estas tres piezas es la base sobre la que construyes cualquier aplicación HANA nativa moderna. Si te falta una sola, no arrancas.

Suscripciones, roles y permisos: la parte que más duele
Antes de escribir una línea de código hay un paso que consume más tiempo del esperado y que provoca la mayoría de los bloqueos iniciales: dejar el entorno listo.
A nivel de subaccount en BTP necesitas, como mínimo:
- Una instancia activa de SAP HANA Cloud.
- La suscripción a Business Application Studio.
- Los roles asignados al usuario para usar BAS y acceder a HANA.
A nivel de HANA Cloud necesitas:
- Crear o disponer de un HDI container donde se desplegará el módulo db.
- Las credenciales y mappings de servicio para que BAS pueda autenticar el deploy.
Los roles más típicos que hay que añadir al usuario son Business_Application_Studio_Developer y los relacionados con el Cloud Foundry space donde corre el HDI. Si saltas este paso o lo haces a medias, lo más probable es que el dev space arranque pero el deploy del módulo db falle con errores poco descriptivos sobre service bindings.
Pitfall habitual: confundir el rol que da acceso al IDE con el rol que da permiso para crear instancias en el Cloud Foundry space. Son dos capas distintas y ambas son necesarias.
Anatomía de un proyecto MTA con módulo db
Cuando creas un proyecto en BAS para HANA Native, lo que generas es un proyecto MTA. Un MTA agrupa varios módulos (db, srv, app, approuter, etc.) que se despliegan juntos como una sola unidad.
Para un proyecto centrado en datos, el módulo clave es el módulo db. Es el que contiene los artefactos que terminarán dentro del contenedor HDI: tablas, vistas, procedimientos, sinónimos, roles y permisos.
La estructura típica de un módulo db es:
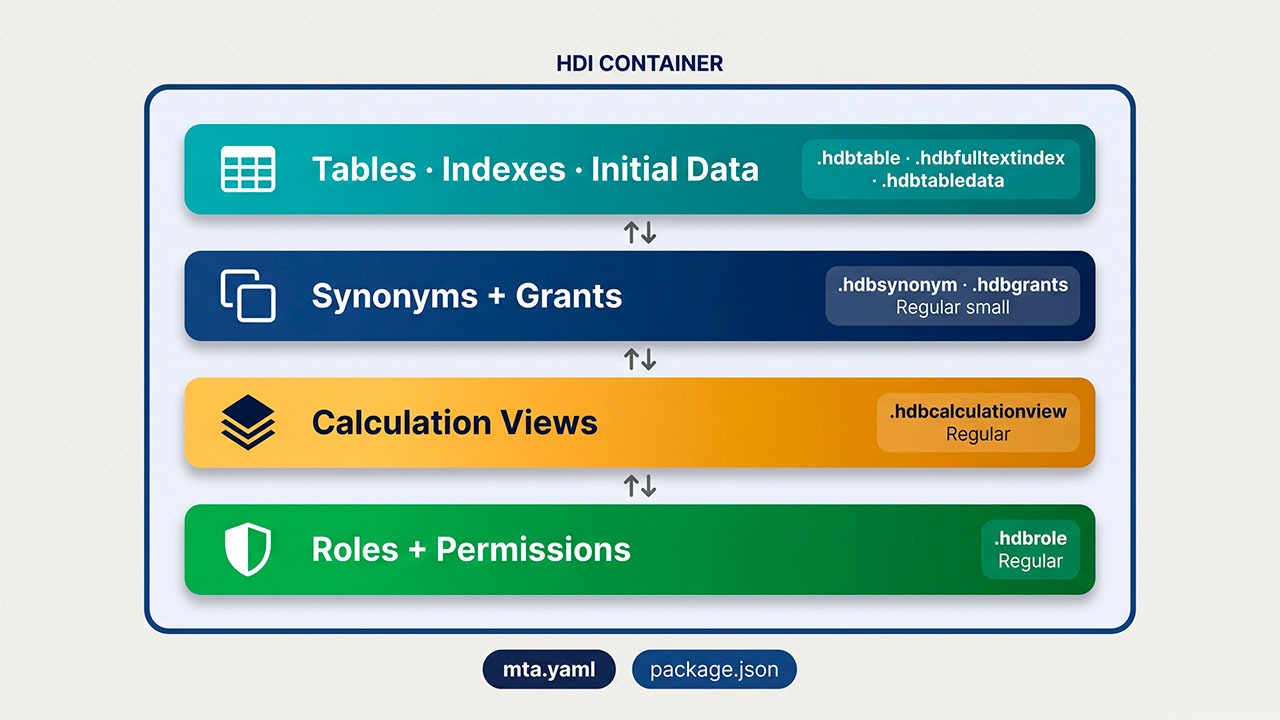
- src/ — donde viven los artefactos (.hdbtable, .hdbcalculationview, .hdbsynonym, etc.).
- cfg/ — para configuraciones que dependen del entorno.
- package.json — define el constructor @sap/hdi-deploy.
- mta.yaml — el descriptor de la aplicación a nivel raíz.
Cada artefacto se declara con su propio fichero, con la extensión que indica su tipo. Esa convención es la que permite que el deployer sepa qué hacer con cada uno: crear tabla, definir vista, generar sinónimo.
La gran ventaja es que todo está versionado en Git como código. La gran desventaja es que la curva de aprendizaje es empinada porque cada tipo de artefacto tiene su propia sintaxis.
Tablas, índices de texto y carga inicial
El primer artefacto que normalmente creas en un módulo db es una tabla.
Los índices de texto en HANA son potentes: soportan búsqueda lingüística, fuzzy y análisis de sentimiento básico, todo en el mismo motor donde viven los datos. No necesitas un Elastic ni un servicio externo para una capa básica de búsqueda.
La carga inicial de datos se gestiona con artefactos .hdbtabledata que apuntan a un fichero CSV. Es el patrón estándar para tener “datos semilla” o configuraciones que viajan con el módulo. Cuidado con usar este mecanismo para datos transaccionales reales: está pensado para datos maestros estables, no para volcar millones de filas.
Esquemas clásicos vs contenedor HDI: el puente con sinónimos
Una de las decisiones más frecuentes en proyectos reales es cómo convivir con datos que ya existen en esquemas clásicos de HANA, fuera del contenedor HDI.
Un contenedor HDI vive en su propio esquema gestionado, aislado y con su propio usuario técnico. No puede acceder directamente a tablas de otro esquema. Si lo intentas, vas a chocar con un error de permisos por mucho que tu usuario humano sí los tenga.
La solución oficial son los sinónimos. Un sinónimo HDI (.hdbsynonym) es un objeto declarativo que dice: “dentro de este contenedor, el nombre RATINGS_EXT apunta a la tabla MI_ESQUEMA.RATINGS_EXT“. Para que ese sinónimo funcione hay que conceder permisos explícitos del esquema clásico al usuario técnico del contenedor, lo que se hace con un .hdbgrants.

Una vez creado el sinónimo, puedes consultar la tabla externa como si fuera local: en vistas, en procedimientos, en cualquier artefacto. Eso te permite construir vistas analíticas que combinan datos modernos (gestionados por tu MTA) con datos legacy (de esquemas clásicos cargados por procesos ETL).
Es un patrón típico en migraciones: el HDI te da gobierno y deploy declarativo, mientras los esquemas clásicos siguen recibiendo datos de los pipelines existentes sin tocar nada.
Vistas de cálculo: del cubo al modelo analítico
Las vistas de cálculo (calculation views) son la joya del modelado HANA. Son vistas declarativas, no SQL, que el motor compila y optimiza. Pueden ser de tres tipos: dimensión, cubo o cubo con star join.
Para reportes y analítica, el tipo más usado es cubo. Un cubo combina
En BAS, las vistas de cálculo se editan con un editor gráfico embebido. Arrastras nodos, configuras joins, defines columnas calculadas. El editor genera por debajo un fichero .hdbcalculationview en XML que es lo que se versiona en Git.
Una buena vista de cálculo no es la que tiene más medidas, sino la que está bien dimensionada: con joins eficientes, sin nodos redundantes y con filtros tan abajo como sea posible para que el motor pueda hacer pruning de particiones y reducir el dataset cuanto antes.

Anonimización en HANA: privacidad por diseño
Esta es una de las capacidades menos conocidas de HANA y, sin embargo, una de las más diferenciales: HANA permite definir anonimización de datos como parte de una vista de cálculo.
Hay dos métodos principales soportados de forma nativa:
- K-anonymity: garantiza que cada combinación de atributos sensibles aparece al menos k veces en el resultado. Si solo hay tres usuarios mayores de 65 en una región, esos registros se generalizan o se suprimen para que no se pueda re-identificar a una persona concreta.
- Differential privacy: introduce ruido estadístico controlado en las medidas, de forma que las agregaciones siguen siendo útiles pero no permiten inferir datos individuales.
La anonimización se configura como una propiedad del nodo de la vista, indicando qué columnas son identificadoras, cuáles son cuasi-identificadoras y cuáles son sensibles. El motor se encarga del resto en tiempo de ejecución.
Esta capacidad es enorme porque el dato anonimizado nace anonimizado en la consulta. No depende de que el desarrollador del CAP, del Fiori o del informe Power BI se acuerde de aplicar la lógica. La privacidad se incrusta en la capa más baja, donde no hay forma de saltársela.
Para casos de uso con datos personales (sanidad, banca, RR.HH., investigación), esto evita un montón de quebraderos de cabeza con cumplimiento de normativas como GDPR.

Buenas prácticas y errores frecuentes
Un proyecto HANA nativo bien construido se nota en detalles:
Los errores que más tiempo cuestan suelen estar en la zona gris entre BTP y HANA: roles mal configurados, mappings de servicio que no se actualizaron tras un redeploy, sinónimos que apuntan a esquemas a los que el contenedor no tiene grant. Cuando algo no funciona y el log no es claro, empieza por ahí.
Otro pitfall típico: editar una vista de cálculo en el editor gráfico, cerrar BAS sin guardar, y descubrir al día siguiente que se perdieron cambios. El editor guarda al fichero .hdbcalculationview, pero confirmar el guardado y hacer commit a Git en el momento es la única forma de no perder trabajo.
Conclusión
El desarrollo nativo sobre SAP HANA dejó de ser un nicho. Es la capa de datos sobre la que se construyen las aplicaciones modernas de BTP y dominarlo marca la diferencia entre un consultor que sabe armar un Fiori y uno capaz de diseñar una solución completa.
Si te llevas tres ideas de aquí, que sean estas:
- El módulo db dentro de un MTA es la unidad de despliegue moderna: tablas, vistas, sinónimos y permisos viajan juntos como código versionado en un contenedor HDI.
- Los sinónimos son el puente con el mundo legacy: te permiten combinar datos del HDI con esquemas clásicos sin romper la encapsulación.
- La anonimización en vistas de cálculo es privacidad por diseño: incrústala en el modelo de datos y no dependas de que cada capa superior se acuerde de aplicarla.
A partir de aquí, el siguiente paso natural es exponer estas vistas vía un módulo srv (CAP, OData) y consumirlas desde un Fiori. Pero esa es otra historia.

Este artículo está basado en el video WEBINAR SAP HANA Native Application en SAP BAS del canal de Logali Group en YouTube.