ABAP
GROUP BY

Contenido
1. GROUP BY para tablas internas.
2. Agrupación por una columna.
3. Agrupación por más de una columna.
Contenido
1. GROUP BY para tablas internas
Esta instrucción está disponible desde “ABAP 7.4”. “GROUP BY” como su nombre lo indica, agrupa las filas de una tabla interna y ejecuta el bucle en estos grupos. Es una variante de la sentencia “LOOP AT”.
“GROUP BY” realiza esta agrupación de filas en base al contenido de las columnas especificadas o a el resultado en las expresiones SQL, cuando estos, sean iguales.
Un requisito previo que tenemos al usar esta sentencia es que podemos seleccionar solo columnas individuales, no todas las columnas de una tabla.
Las filas están vinculadas directamente a un GRUPO que pertenece a una clave de grupo o “GROUP KEY”, esta está especificada tras la sentencia “GROUP BY“, la cuál se aplica en cada bucle o iteración del “LOOP AT”.
Primero ejecuta este bucle “LOOP AT” con el grupo que se crea mediante la condición de “GROUP BY”. Luego, se realiza un bucle para cada grupo, esto para acceder a las filas de cada grupo, y estos serían los miembros.
Veámoslo en un ejemplo, primero agrupando por una columna:
2. Agrupación por una columna
Lo primero que realizamos, es llenar de registros una tabla interna llamada “GT_SPFLI” en base a la tabla estándar de SAP “SPFLI” con todos sus campos.
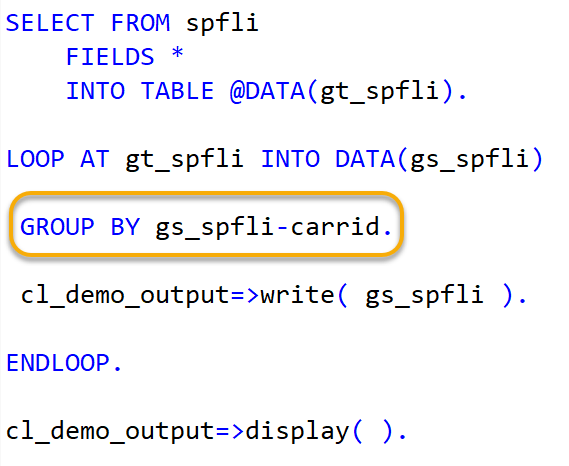
Realizamos una iteración “LOOP AT” para cada registro de la tabla interna y lo asignamos a la estructura “GS_SPFLI”. Dentro del bloque de “LOOP”, vamos a agregar la instrucción “GROUP BY” para que se agrupen las filas por el campo “CARRID”.
Al añadir “GROUP BY”, el “LOOP” se procesa en dos etapas:
- En la primera, todas las filas especificadas en la condición se leen en el orden de procesamiento que se haya indicado
- Para cada fila leída se construye una clave de grupo, es decir, la que se haya especificado después de la sentencia “GROUP BY”
- Cada clave de grupo representa un grupo y cada fila se asigna precisamente a un grupo, como miembro
- Si no se usa la adición “WITHOUT MEMEBERS”, esta asignación es interna y puede utilizarse para acceder a los miembros de un grupo en la segunda etapa
En la segunda etapa, se ejecuta el bucle en todos los grupos, es decir, las sentencias entre el bloque de “LOOP/ENDLOOP” se ejecutan en cada iteración.
Se leen las filas de cada grupo. El orden por defecto de los grupos se basa en el momento en que se crea por primera vez su clave de grupo.
Al ejecutar este programa, obtenemos los siguientes resultados:

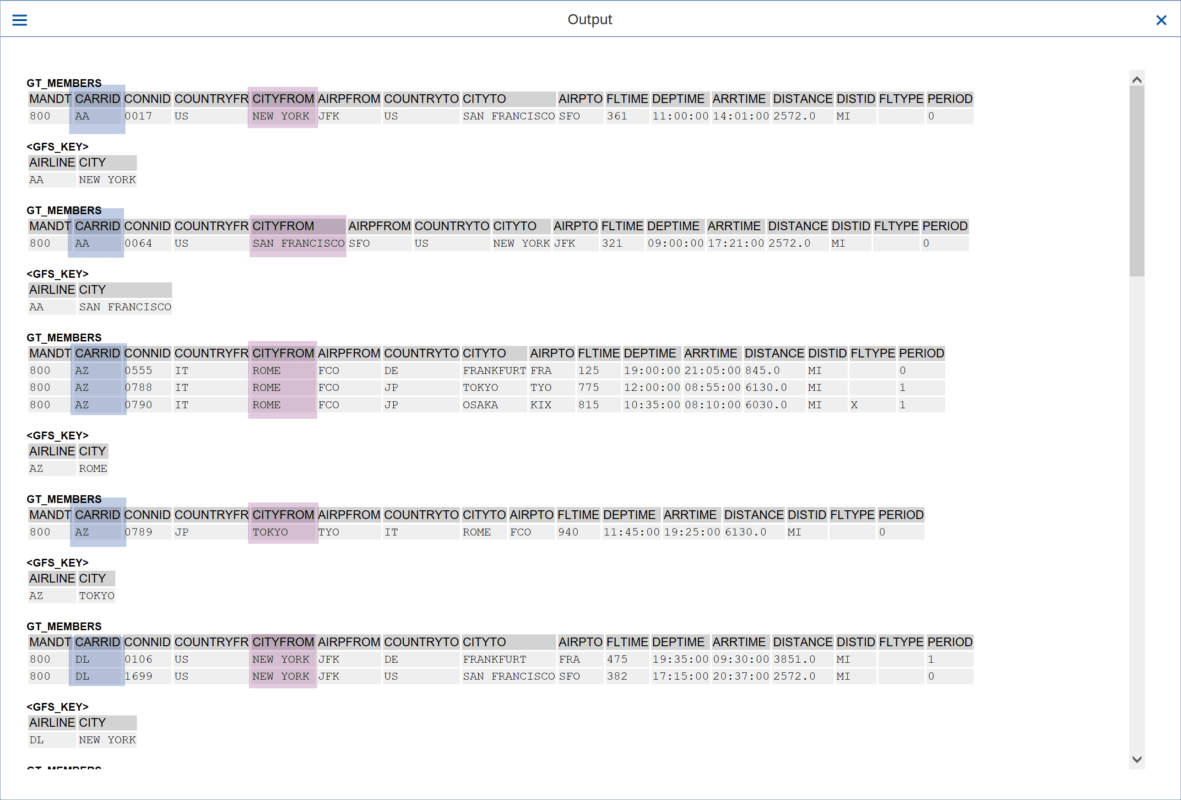
Como podemos ver dentro del “LOOP” accedemos a “GS_SPFLI” específicamente al campo “CARRID”. Cada estructura contiene la primera línea de cada grupo creado por “GROUP BY”.
Ahora, para acceder a los miembros de cada grupo, agregaremos un segundo “LOOP” sobre los grupos creados en la primera parte. La tabla interna no puede modificarse en el bucle de grupo a menos que se especifique la adición “WITHOUT MEMBERS”.
Declaramos entonces la variable “GT_MEMBERS” es una variable el tipo de línea “GT_SPFLI”
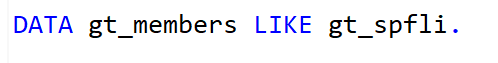
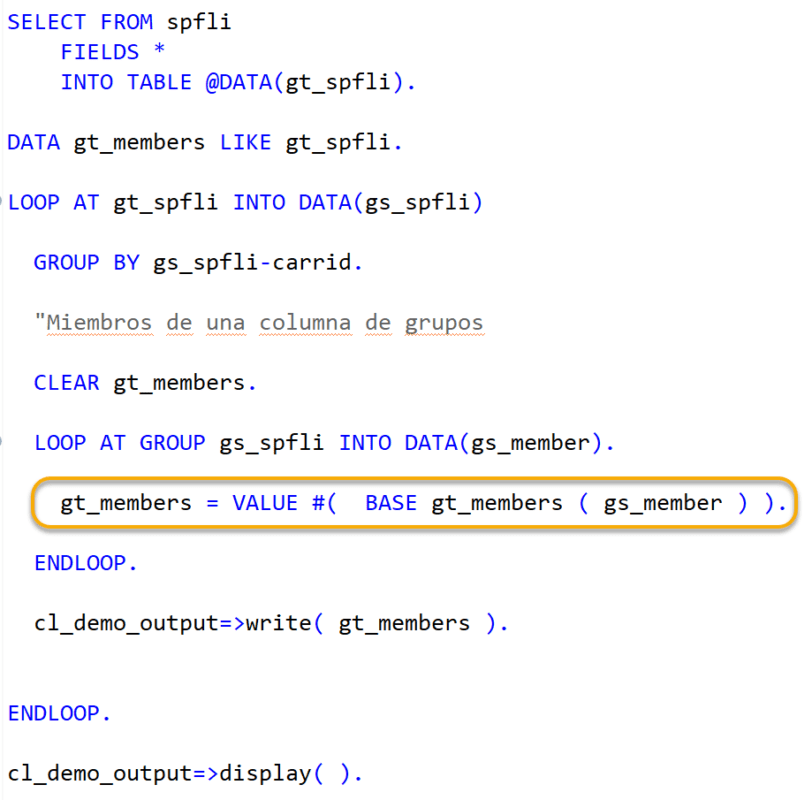
Agregamos “LOOP AT GROUP” e iteramos la estructura “GS_SPFLI”. Declaramos una variable llamada “GS_MEMBER”, esta es una estructura con el tipo de línea igual a “GT_SPFLI” y contiene los miembros de cada grupo.
Le damos valor a “GT_MEMBERS”, entonces mediante “VALUE #” y dentro de paréntesis usamos la sentencia “BASE”, la cual ayuda a conservar el valor original, es decir, se conservan los registros anteriores. Se puede usar para especificar una base de valor inicial para la nueva estructura o tabla interna
Aquí en este ejemplo, tomaremos como base el valor que venga de “GT_MEMBERS” y le sumaremos el registro de “GS_MEMBER” en cada iteración, esto clasificado por cada grupo.
Al ejecutar este programa, obtenemos los siguientes resultados:
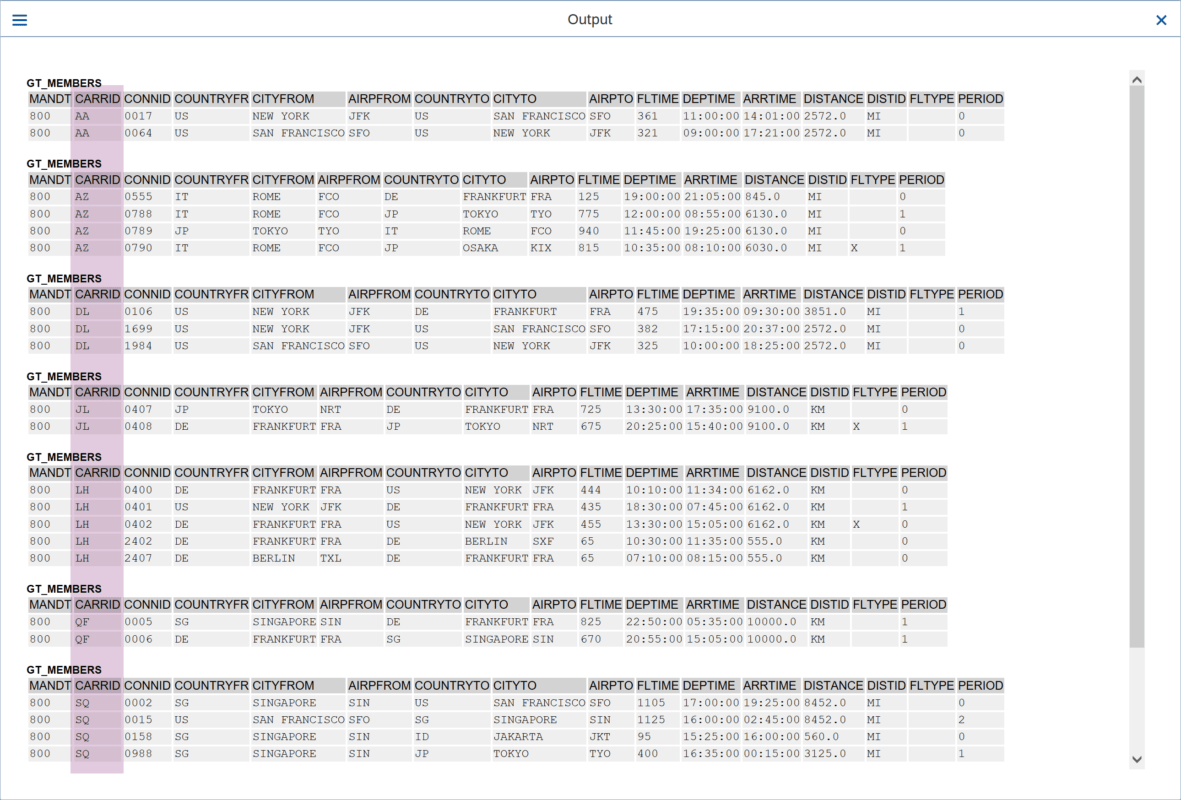
Vemos que se muestran los miembros de cada grupo, organizados por la cada clave de grupo en este caso, solo agrupados por el campo “CARRID”.
1. Agrupación por más de una columna
También es posible, agrupar por más de una columna, en este caso, añadimos otro criterio de agrupación.
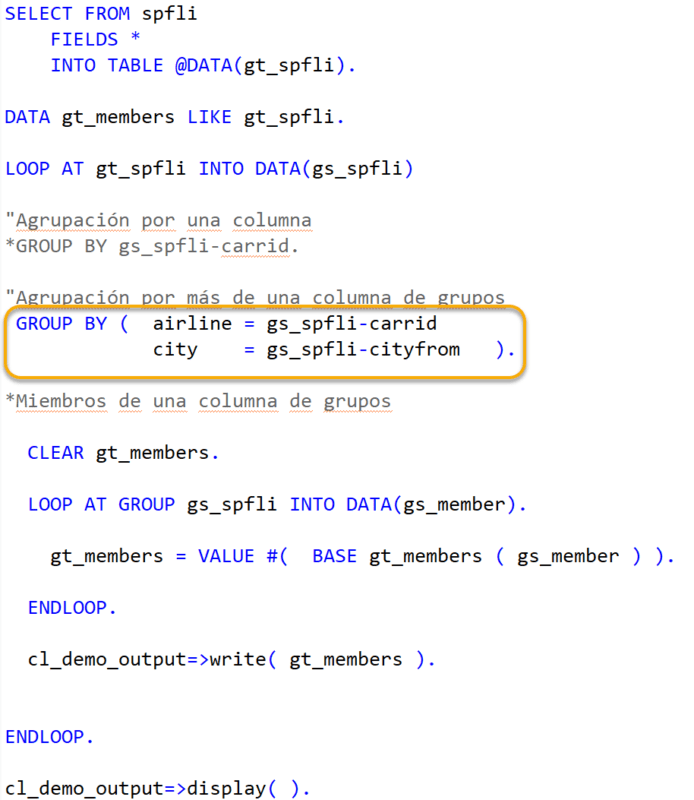
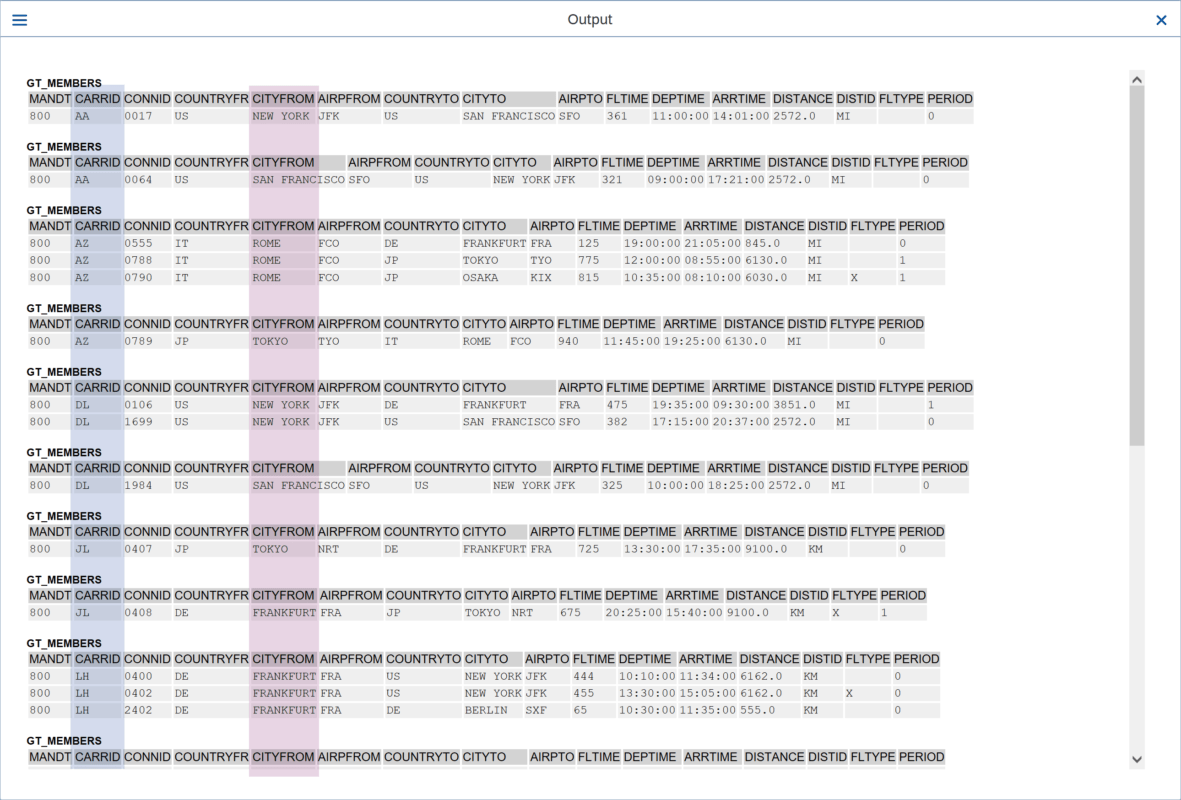
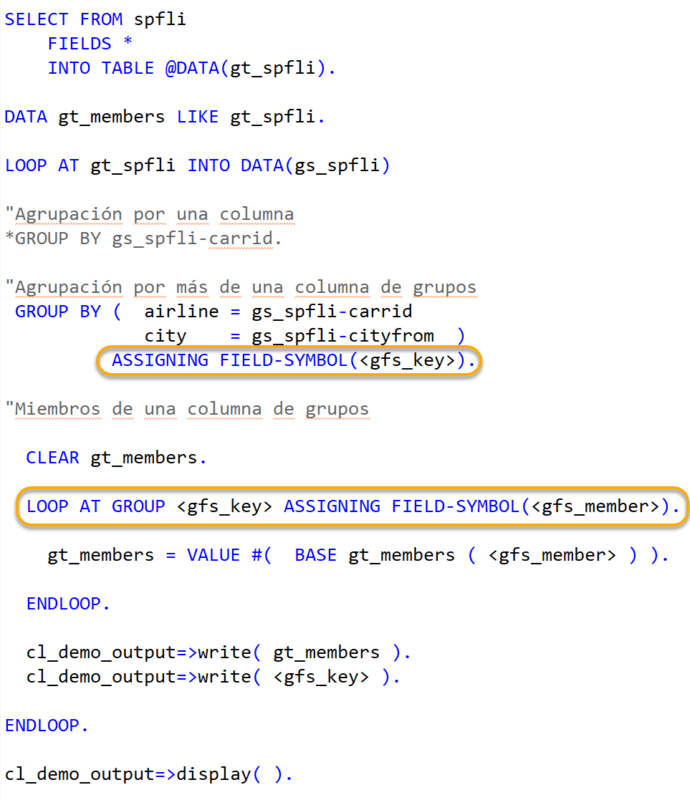
En este caso se construye una estructura por la clave de grupo, entonces asignamos un nombre a nuestras claves de grupo y le asignamos los campos, en este caso “CARRID” y “CITYFROM”. Y dejamos la misma lógica para acceder a los miembros de los grupos.
Al ejecutar este programa, obtenemos los siguientes resultados:
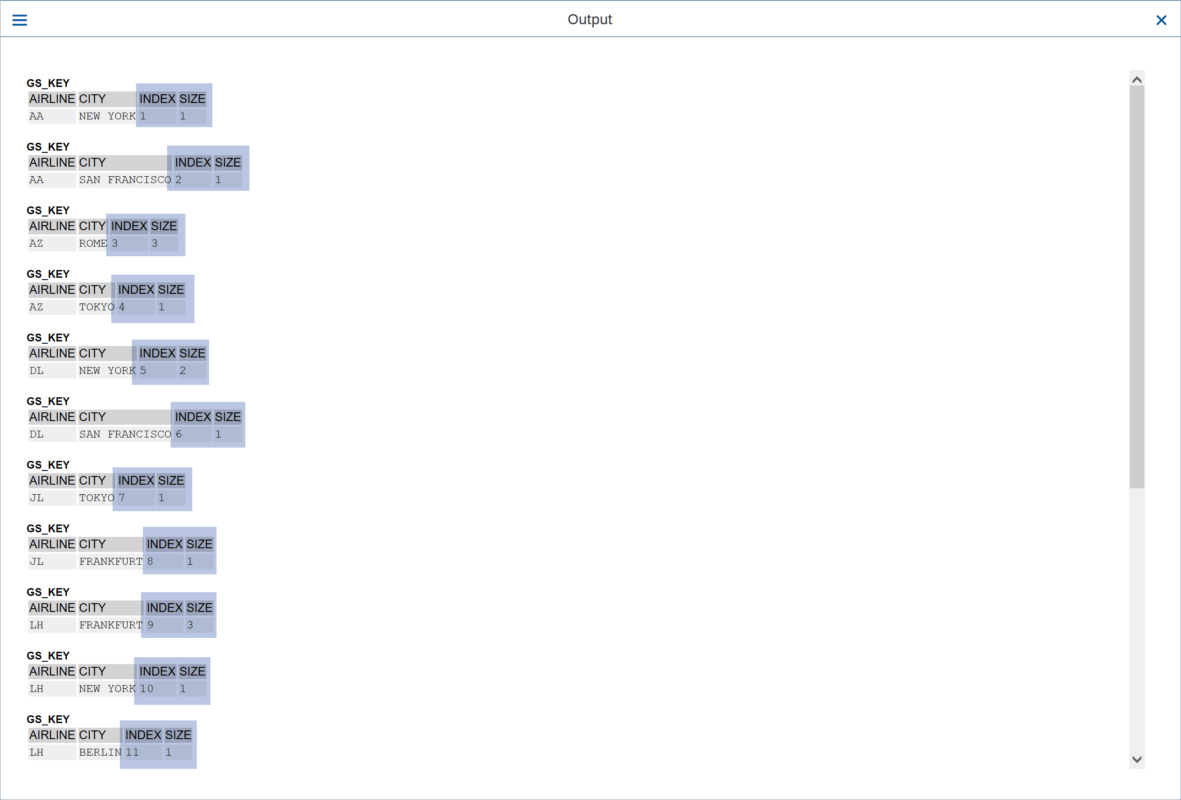
1. Clave de grupo
También es posible, establecer una clave de grupo, es decir, declarar en línea en la sentencia “GROUP BY” una clave que reúne los campos.
En lugar de reutilizar la estructura “GS_SPFLI”, se usa una clave que declaramos en línea. Esta es llamada “GROUP KEY BINDING”, de esta forma se ofrecen más funciones como la adición “WITHOUT MEMBERS”, “GROUP SIZE”, “GROUP INDEX”).
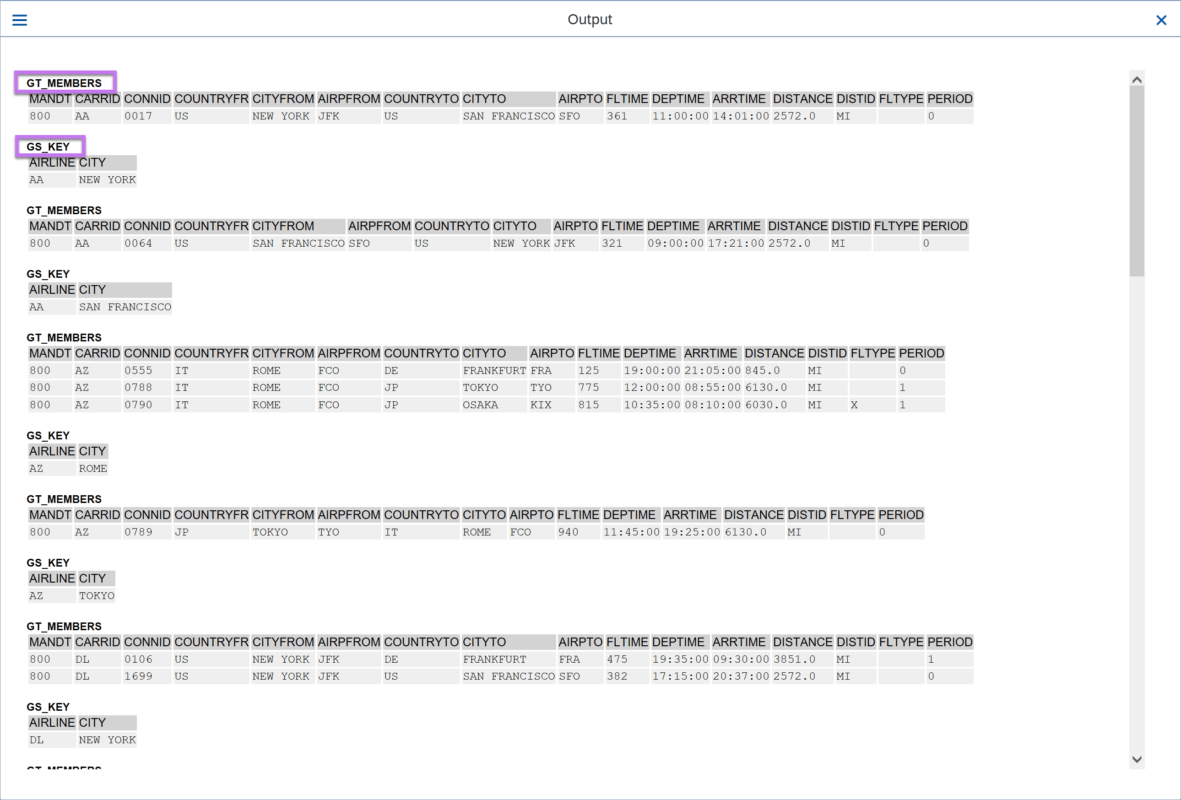
Ahora se accede al grupo utilizando la clave “GS_KEY”, esta es una estructura con los componentes “AIRLINE” y “CITY”.

Al ejecutar este programa, obtenemos los siguientes resultados:
Podemos usar también “FIELD SIMBOLS”, dentro del “LOOP” para acceder al grupo. Y así mejorar el rendimiento de nuestro programa.
El primer “LOOP” es en donde se usa una clave para crear los grupos, y en el segundo “LOOP”, se recorren los grupos del primero “LOOP” y se agrega la lógica para acceder a los miembros de dicho grupo.
Al ejecutar este programa, obtenemos los siguientes resultados:
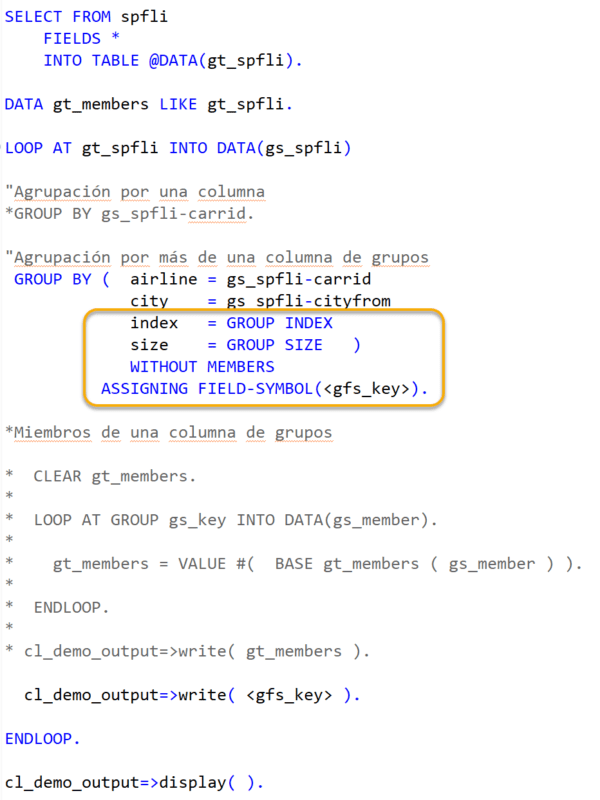
También, podemos utilizar la adición “WITHOUT MEMBERS” para ahorrar tiempo de ejecución y memoria.
Con “WITHOUT MEMBERS” no es posible usar “LOOP” para “GT_MEMBERS”, pero “GS_KEY” cuenta con algunos componentes opcionales predefinidos para obtener información adicional, como el “GROUP INDEX” y “GROUP SIZE” de los grupos.
Al ejecutar este programa, obtenemos los siguientes resultados: